Race conditions guide
Guía sobre Race Condition

Certificaciones
- eWPT
- eWPTXv2
- OSWE
- BSCP
Descripción
Explicación técnica de la vulnerabilidad race condition. Detallamos cómo identificar y explotar estas vulnerabilidad. Además, exploramos estrategias clave para prevenirla
¿Qué es una race condition?
Las race conditions son un tipo común de vulnerabilidad estrechamente relacionada con los fallos de lógica de negocio. Ocurren cuando los sitios web procesan solicitudes de forma concurrente sin los mecanismos de protección adecuados. Esto puede hacer que múltiples hilos distintos interactúen con los mismos datos al mismo tiempo, lo que resulta en una colisión que provoca un comportamiento no deseado en la aplicación. Un ataque de race condition utiliza solicitudes enviadas con una sincronización precisa para causar colisiones intencionadas y explotar este comportamiento no deseado con fines maliciosos
El período de tiempo durante el cual una colisión es posible se conoce como race window. Esto podría ser la fracción de segundo entre dos interacciones con la base de datos, por ejemplo
Al igual que otros fallos de lógica, el impacto de una race condition depende en gran medida de la aplicación y de la funcionalidad específica en la que ocurra
Limit overrun race condition
El tipo más conocido de race condition nos permite exceder algún tipo de límite impuesto por la lógica de negocio de la aplicación
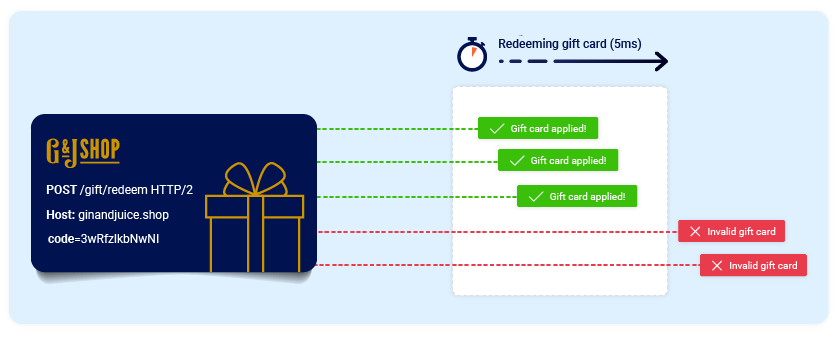
Por ejemplo, consideremos una tienda en línea que nos permite ingresar un código promocional durante el pago para obtener un descuento único en nuestro pedido. Para aplicar este descuento, la aplicación puede realizar los siguientes pasos de alto nivel:
Verificar que no hayamos usado antes este
códigoAplicar el
descuentoaltotal del pedidoActualizar el
registroen labase de datospara reflejar que ya hemos utilizado estecódigo
Si más tarde intentamos reutilizar este código, las verificaciones iniciales realizadas al inicio del proceso deberían evitar hagamos esto:
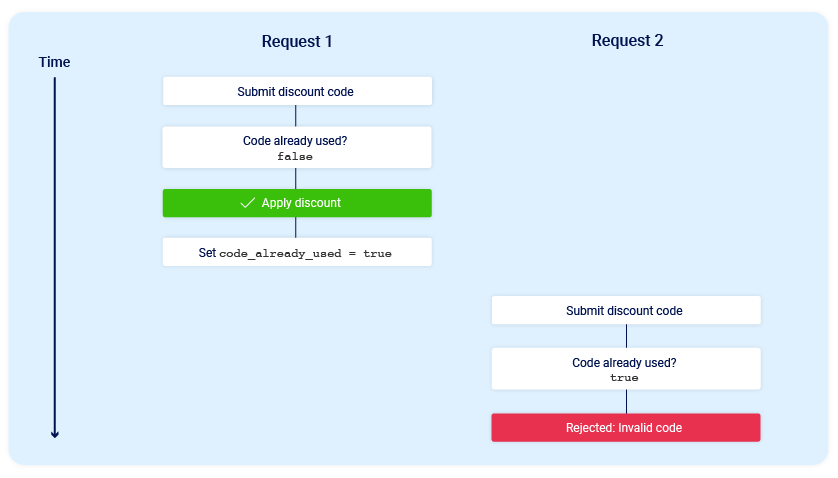
Ahora consideremos qué sucedería si un usuario que nunca ha aplicado este código de descuento antes intenta aplicarlo dos veces casi al mismo tiempo

Como podemos ver, la aplicación pasa por un subestado temporal, es decir, un estado al que entra y sale antes de que finalice el procesamiento de la solicitud. En este caso, el subestado comienza cuando el servidor empieza a procesar la primera solicitud y finaliza cuando actualiza la base de datos para indicar que ya hemos utilizado este código. Esto introduce una pequeña race window durante la cual podemos reclamar el descuento tantas veces como queramos
Existen muchas variantes de este tipo de ataque. Por ejemplo:
Canjearunatarjeta de regalovarias vecesCalificarunproductovarias vecesRetirarotransferirefectivo en excesodelsaldode nuestracuentaReutilizaruna únicasolución CAPTCHABypassearunlímite de velocidadde peticionesanti fuerza bruta
Las limit overrun race conditions son un subtipo de las llamadas fallas de time-of-check to time-of-use (TOCTOU)
Detectando y explotando una limit overrun race condition
El proceso de detectar y explotarlas es relativamente sencillo. En términos generales, solo necesitamos lo siguiente:
Identificarunendpointdeuso únicoo conlímite de velocidadque tenga algúnimpacto en la seguridado en algún otropropósito útilEnviarmúltiplessolicitudesa esteendpointenrápida sucesiónpara ver si podemossobrepasarestelímite
El principal desafío es sincronizar las solicitudes para que al menos dos race windows coincidan, causando una colisión. Esta ventana suele durar solo unos milisegundos y puede ser incluso más corta
Aunque enviemos todas las solicitudes exactamente al mismo tiempo, existen diversos factores externos incontrolables e impredecibles que afectan el momento en que el servidor procesa cada solicitud y en qué orden
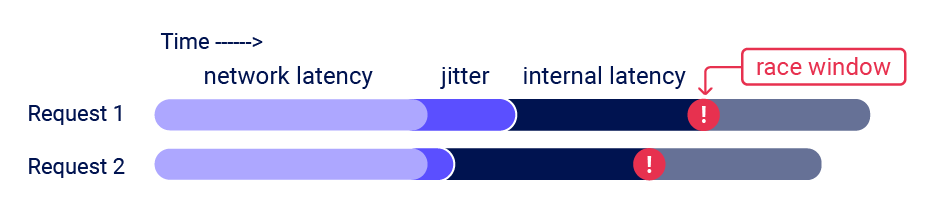
Desde el Repeater de Burpsuite podemos enviar fácilmente un grupo de solicitudes en paralelo de una manera que se reduce significativamente el impacto de uno de estos factores, específicamente el del network jitter (variabilidad de latencia en la red). Burpsuite ajusta automáticamente la técnica que utiliza según la versión de HTTP soportada por el servidor
Para
HTTP/1, utiliza la clásicatécnicadelast-byte synchronizationPara
HTTP/2, utiliza latécnicadesingle-packet attack
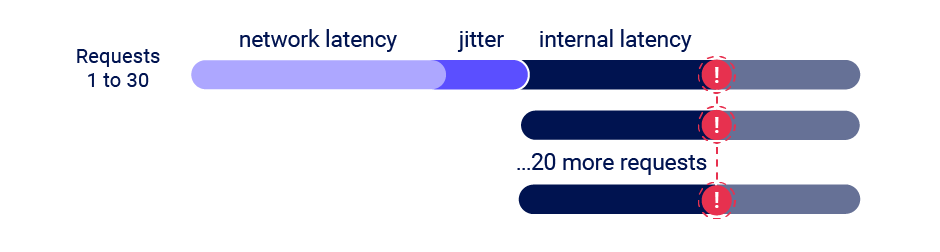
El single-packet attack permite neutralizar completamente la interferencia del network jitter utilizando un único paquete TCP para completar de 20 a 30 solicitudes simultáneamente. Aunque a menudo, podemos usar solo dos solicitudes para activar un exploit, enviar un gran número de solicitudes de esta manera ayuda a mitigar la latencia interna, también conocida como server-side jitter. Esto es especialmente útil durante la fase inicial de descubrimiento
En este laboratorio vemos como aplicar esta técnica:
- Limit overrun race conditions - https://justice-reaper.github.io/posts/Race-Conditions-Lab-1/
Detecta y explotando una limit overrun race condition con la extensión Turbo Intruder de Burpsuite
Además de proporcionar soporte nativo para el single-packet attack mediante el Repeater, también podemos usar la extensión Turbo Intruder de Burpsuite para llevar a cabo este ataque. Turbo Intruder requiere tener cierta experiencia en Python, pero es adecuado para ataques más complejos, como aquellos que requieren múltiples reintentos, temporización escalonada de solicitudes o un número extremadamente alto de peticiones
Para usar el single-packet attack en Turbo Intruder debemos seguir los siguiente pasos:
Asegurarque elobjetivoadmiteHTTP/2, ya que este ataque no escompatibleconHTTP/1Configurar el
motor de solicitudesestableciendoengine=Engine.BURP2yconcurrentConnections=1Al
enviar solicitudes,agruparlasasignándolas a unagatemediante el argumentogateen el métodoengine.queue()Para
enviartodas lassolicitudesde ungrupo, abrir lagatecorrespondiente con el métodoengine.openGate()
1
2
3
4
5
6
7
8
9
10
11
def queueRequests(target, wordlists):
engine = RequestEngine(endpoint=target.endpoint,
concurrentConnections=1,
engine=Engine.BURP2)
# queue 20 requests in gate '1'
for i in range(20):
engine.queue(target.req, gate='1')
# send all requests in gate '1' in parallel
engine.openGate('1')
Para más detalles, debemos consultar la plantilla race-single-packet-attack.py que se encuentra en el directorio de ejemplos predeterminado del Turbo Intruder
En este laboratorio vemos como aplicar esta técnica:
- Bypassing rate limits via race conditions - https://justice-reaper.github.io/posts/Race-Conditions-Lab-2/
Secuencias ocultas en múltiples pasos
En la práctica, una sola solicitud puede iniciar una secuencia de múltiples pasos, haciendo que la aplicación pase por múltiples estados ocultos a los que entra y luego sale antes de que se complete el procesamiento de la solicitud. Nos referimos a estos como subestados
Si identificamos una o más solicitudes HTTP que causan una interacción con los mismos datos, podemos abusar de estos subestados para exponer variaciones sensibles al tiempo, este tipo de fallos lógicos son comunes en los flujos de trabajo que requieren múltiples pasos. Esto permite explotaciones de race condition que van mucho más allá de simplemente exceder algún tipo de límite
Por ejemplo, podemos estar familiarizados con los flujos de trabajo defectuosos de la autenticación multifactor (MFA) que nos permiten realizar la primera parte del inicio de sesión utilizando credenciales conocidas, y luego navegar directamente a la aplicación forzando la navegación y evitando así, la MFA por completo
El siguiente pseudocódigo demuestra cómo un sitio web podría ser vulnerable a una variación de race condition de este ataque
1
2
3
4
5
6
session['userid'] = user.userid
if user.mfa_enabled:
session['enforce_mfa'] = True
# generate and send MFA code to user
# redirect browser to MFA code entry form
Como podemos ver, esto es en realidad una secuencia de múltiples pasos dentro del intervalo de una sola solicitud. Lo más importante es que la aplicación pasa por un subestado en el que el usuario tiene temporalmente una sesión iniciada válida, pero la MFA aún no se está aplicando. Un atacante podría explotar esto enviando una solicitud de inicio de sesión junto con una solicitud a un endpoint que contenga información importante, al estar autenticados podemos obtener información sensible bypasseando el MFA
Como estas vulnerabilidades son bastante específicas de cada aplicación, es importante primero comprender la metodología general que debemos aplicar para identificarlas de manera eficiente
Metodología
Para detectar y explotar estas secuencias ocultas de múltiples pasos, es recomendable seguir la metodología que se va a explicar a continuación. Esta metodología es un resumen de este artículo https://portswigger.net/research/smashing-the-state-machine
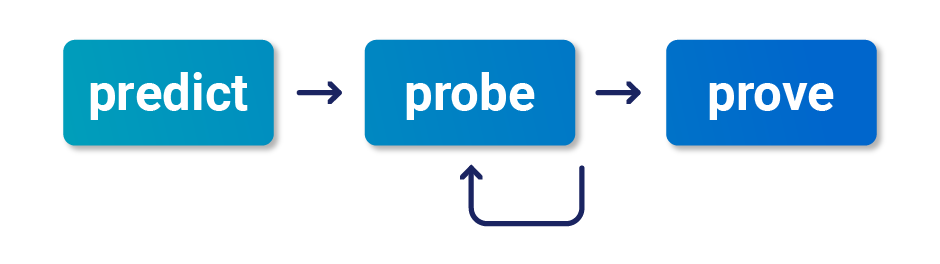
1 - Predecir colisiones potenciales
Testear cada endpoint no es práctico. Después de mapear el sitio objetivo, podemos reducir la cantidad de endpoints que necesitamos testear haciéndonos las siguientes preguntas:
¿Es este endpoint crítico para la seguridad?- Muchosendpointsno afectanfuncionalidades críticas, por lo que no vale la penaprobarlos¿Existe potencial de colisión?- Para unacolisión exitosa, generalmente se requierendos o más solicitudes que desencadenen operaciones en el mismo registro
Por ejemplo, consideremos las siguientes variaciones de una implementación de restablecimiento de contraseña. Con el primer ejemplo, solicitar un restablecimiento de contraseña en paralelo para dos usuarios diferentes es poco probable que cause una colisión, ya que son cambios en dos registros diferentes. Sin embargo, la segunda implementación permite editar el mismo registro con solicitudes para dos usuarios diferentes
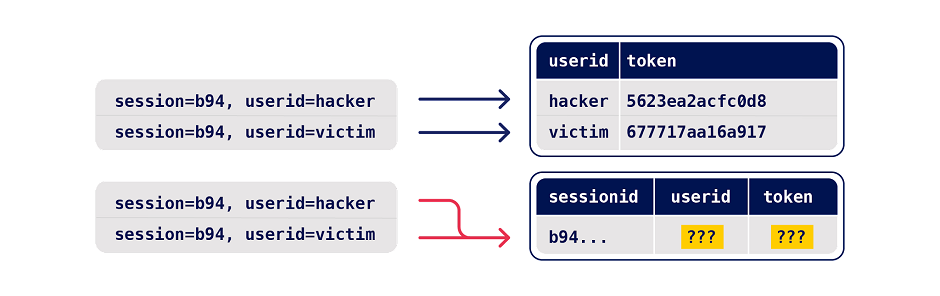
2 - Buscar pistas
Para buscar pistas, primero debemos medir cómo se comporta el endpoint bajo condiciones normales. Podemos hacer esto desde el Repeater, lo primero es agrupar todas las solicitudes y posteriormente utilizar la opción Send group in sequence (separate connections)
En este tipo de solicitud, el Repeater establece una conexión con el objetivo, envía la solicitud desde la primera pestaña y luego cierra la conexión, posteriormente repite este proceso para todas las demás pestañas en el orden en que están dispuestas en el grupo. Enviar las solicitudes a través de separate connections facilita testear vulnerabilidades que requieren de múltiples pasos
También podemos utilizar Send group in sequence (single connection), el Repeater establece una conexión con el objetivo, envía las solicitudes de todas las pestañas en el grupo y luego cierra la conexión
Enviar solicitudes a través de una única conexión te permite probar posibles vectores de desincronización del lado del cliente. También reduce el jitter que puede ocurrir al establecer conexiones TCP. Esto es útil para ataques basados en tiempo que dependan de poder comparar respuestas con diferencias muy pequeñas en los tiempos de respuesta
Para enviar una secuencia de solicitudes, el grupo debe cumplir con los siguientes criterios:
No debe haber ninguna
pestañademensaje WebSocketen el grupoNo debe haber ninguna
pestaña vacíaen el grupo
Existen algunos criterios adicionales para enviar una secuencia de solicitudes a través de una única conexión:
Todas las
pestañasdeben tener el mismoobjetivoTodas las
pestañasdeben usar la mismaversión de HTTP, es decir, deben usar todasHTTP/1o todasHTTP/2
En el caso de las solicitudes en paralelo, el Repeater envía las solicitudes de todas las pestañas del grupo a la vez. Esto resulta útil para identificar y explotar las race conditions
El Repeater sincroniza las solicitudes en parelelo para garantizar que todas lleguen completas y simultáneamente. Utiliza diferentes técnicas de sincronización según la versión de HTTP que esté siendo utilizada. Por ejemplo:
Al
enviarporHTTP/1, elRepeaterutiliza la técnica delast-byte sync. En este caso, se envían variassolicitudesa través deconexiones simultáneas, pero se retiene elúltimo bytede cadasolicitud del grupo.Tras un breve retraso, estos últimos bytes se envían simultáneamente por cada conexiónAl
enviarporHTTP/2+,el Repeater envía el grupo mediante un single-packet attack. En este caso,se envían múltiples solicitudes mediante un solo paquete TCP
Cuando seleccionamos una pestaña que contiene una respuesta a una solicitud en pararelo, un indicador en la esquina inferior derecha muestra el orden en que se recibió esa respuesta dentro del grupo (por ejemplo, 1/3, 2/3)
Debemos tener en cuenta que no se pueden enviar solicitudes en paralelo usando macros. Esto se hace para evitar que las macros interfieran con la sincronización de solicitudes
Para enviar un grupo de solicitudes en paralelo, el grupo debe cumplir dos criterios:
Todas las
solicitudes del grupodeben utilizar los mismosprotocolos de host,puertoycapa de transporteNo se debe habilitar
HTTP/1 keep-alivepara elproyecto
Una vez aclarado esto, el siguiente paso es enviar el mismo grupo de solicitudes a la vez utilizando el single-packet attack o el last-byte sync si la web no soporta HTTP/2, esto se hace para minimizar el network jitter. Podemos hacer esto desde el Repeater seleccionando la opción Send group in pararell (single-packet attack) o la extensión Turbo Intruder de Burpsuite
Cualquier cosa puede ser una pista. Solo debemos buscar alguna forma de desviación de lo que observamos durante el benchmarking. Esto incluye un cambio en una o más respuestas, pero no debemos olvidar los efectos de segundo orden, como diferentes contenidos de correo electrónico o un cambio visible en el comportamiento de la aplicación después del ataque
3 - Prueba de concepto
Debemos tratar de entender lo que está ocurriendo, eliminar las solicitudes superfluas y asegurarnos de que podemos replicar los efectos después de eliminarlas
Las advanced race conditions pueden causar comportamientos inusuales y únicos, por lo que la forma para obtener el máximo impacto no siempre es obvia de inmediato. Puede ayudar, pensar que cada race condition es como una debilidad estructural,en lugar de una vulnerabilidad aislada
Multi-endpoint race condition
Quizá la forma más intuitiva de race conditions son aquellas que implican enviar solicitudes a múltiples endpoints al mismo tiempo, a este tipo de race conditions se les llama multi-endpoint race conditions. Por ejemplo, estamos comprando en una tienda online, añadimos un artículo al carrito y posteriormente pagamos ese artículo, pero antes de que la página de confirmación del pedido se cargue por completo, rápidamente añadimos otro artículo al carrito y forzamos la navegación a la página de confirmación. En este escenario, podríamos encontrarnos con una race condition donde el sistema no ha terminado de procesar el primer pago antes de que intentemos añadir el segundo artículo. Podemos aprovechar esto, por ejemplo, para obtener más productos a un precio menor del estipulado
Una variación de esta vulnerabilidad puede ocurrir cuando la validación de pago y la confirmación del pedido se realizan durante el procesamiento de una única petición. El diagrama de estado para el estado del pedido podría ser similar a este, en este caso, podemos añadir más artículos a nuestro carrito durante la race window, es decir, el momento entre que se valida el pago y cuando el pedido se confirma

Alineando las multi-endpoint race windows
Al probar las multi-endpoint race conditions, podríamos encontrar problemas al intentar alinear las race window para cada solicitud, incluso si las enviamos todas al mismo tiempo utilizando un single-packet attack
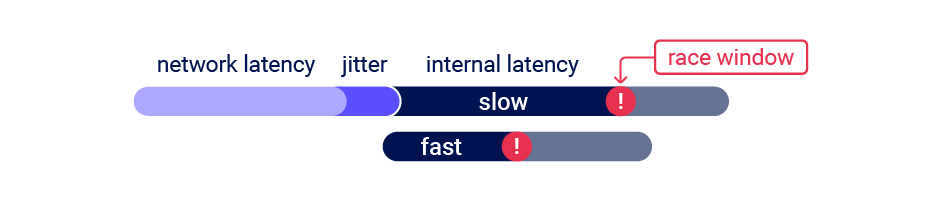
Este problema común es causado principalmente por los siguientes dos factores:
Retrasos introducidos por la arquitectura de red- Por ejemplo, puede haber unretrasocada vez queel front-end establece una nueva conexión con el back-end.El protocolo utilizado también puede tener un gran impactoRetrasos introducidos por el procesamiento específico del endpoint- Lostiempos de procesamientode losendpointsvarían , a veces de manera significativa, dependiendo de lasoperacionesquedesencadenan
Afortunadamente, existen posibles soluciones alternativas para ambos problemas
Connection warming
El delay en las conexiones del back-end normalmente no interfiere con los race condition attacks porque generalmente retrasa las solicitudes de manera equivalente, por lo que las solicitudes permanecen sincronizadas
Es esencial poder distinguir este tipo de delays de aquellos causados por factores específicos del endpoint. Una forma de hacerlo es "calentando" la conexión con una o más solicitudes sin importancia para ver si esto reduce los tiempos de procesamiento de las solicitudes. Desde Repeater, podemos intentar agregar una solicitud GET para la pestaña de login de nuestro grupo y luego usar la opción Send group in sequence (single connection)
Si la primera solicitud aún tiene un tiempo de procesamiento más largo, pero el resto de las solicitudes ahora se procesan dentro de corto período de tiempo , podemos ignorar el retraso aparente y continuar testeando de manera normal
Si aún vemos tiempos de respuesta inconsistentes en un endpoint, incluso usando un single-packet attack, esto es una indicación de que el delay en la respuesta del back-end está interfiriendo con nuestro ataque. Podemos ser capaces de sortear esto utilizando la extensión Turbo Intruder para enviar algunas solicitudes de "calentamiento" de la conexión antes de seguir con las solicitudes principales de nuestro ataque
En este laboratorio vemos como aplicar esta técnica:
- Multi-endpoint race conditions - https://justice-reaper.github.io/posts/Race-Conditions-Lab-3/
Abusing rate or resource limits
Si el connection warming no funciona, existen varias soluciones a este problema. Podemos usar el Turbo Intruder para provocar un delay en el front-end, sin embargo, como esto implica dividir las solicitudes del ataque en varios paquetes TCP, no podremos usar la técnica del single-packet attack. Como resultado, es poco probable que el ataque funcione correctamente en los objetivos que tengan un delay altamente variable (jitter), sin importar el delay que le configuremos al front-end 
En su lugar, podemos solucionar este problema si nos aprovechamos de una característica de seguridad común. Para ello, debemos saber primero que es el rate limit y el resource limit:
Rate limit- Es unmecanismodeseguridadquerestringelacantidaddesolicitudesque unclientepuedeenviara unservidoren unperíodo de tiempo determinado. Si seexcedeestelímite, elservidorpuederetrasarorechazarlassolicitudes adicionalesResource limit- Son lasrestriccionesqueimponeunservidorparaevitarque se leagotenlosrecursos (como memoria, CPU o conexiones)cuandose reciben demasiadas solicitudes
Los servidores web a menudo retrasan el procesamiento de solicitudes si se envían demasiadas demasiado rápido. Al enviar una gran cantidad de solicitudes para activar intencionalmente el rate limit o el resource limit, podemos ser capaces de causar la cantidad de delay necesario en el back-end. Esto hace que el single-packet attack sea viable incluso cuando se requiere que se ejecute con delay

Single-endpoint race conditions
Enviar peticiones en paralelo con diferentes valores a un mismo endpoint a veces puede desencadenar importantes race conditions, a este tipo de race condition se le llama single-endpoint race condition
Por ejemplo, consideremos un mecanismo de restablecimiento de contraseña que almacena el ID de usuario y el token de restablecimiento en la sesión del usuario. En este escenario, enviar dos solicitudes de restablecimiento de contraseña en paralelo desde la misma sesión, pero con dos nombres de usuario diferentes, podría causar esta colisión
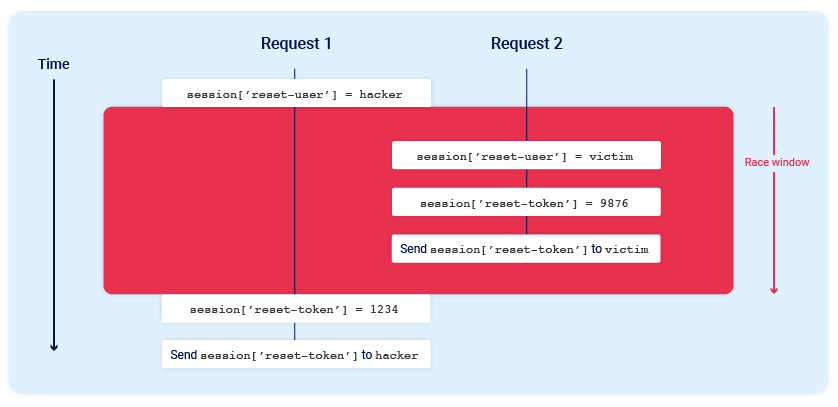
Este sería el estado final cuando todas las operaciones se han completado:
1
2
session['reset-user'] = victim
session['reset-token'] = 1234
La sesión ahora contiene el ID de usuario de la víctima, pero el token válido de restablecimiento se envía al atacante
Para que este ataque funcione, las diferentes operaciones realizadas por cada proceso deben ocurrir en el orden correcto. Probablemente se requieran múltiples intentos o un poco de suerte para lograr el resultado deseado
Las confirmaciones de correo electrónico o cualquier operación basada en emails suelen ser un buen objetivo para single-endpoint race conditions. Esto es debido a que los emails a menudo se envían mediante un hilo en segundo plano después de que el servidor emita la respuesta HTTP al cliente, lo que hace que las race conditions sean más probables
En este laboratorio vemos como aplicar esta técnica:
- Single-endpoint race conditions - https://justice-reaper.github.io/posts/Race-Conditions-Lab-4/
Mecanismos de bloqueo basados en la sesión
Algunos frameworks intentan evitar la corrupción accidental de datos mediante algún tipo de bloqueo de solicitudes. Por ejemplo, el módulo nativo de PHP para el manejo de sesiones solo procesa una solicitud por sesión a la vez
Es fundamental detectar este tipo de comportamiento, ya que puede ocultar vulnerabilidades. Si observamos que todas las solicitudes se procesan secuencialmente, podemos intentar enviar cada una con un token de sesión diferente
Ataques sensibles al tiempo
A veces podemos no encontrar condiciones de carrera, pero las técnicas para enviar solicitudes con un timing preciso aún pueden revelar la presencia de otras vulnerabilidades
Un ejemplo es cuando se utilizan high-resolution timestamps en lugar de cadenas aleatorias criptográficamente seguras para generar tokens de seguridad. Un ejemplo de high-resolution timestamp puede ser 1700000000, esto es un timestamp pero se usan más digitos para hacerlo más preciso
Consideremos un token de restablecimiento de contraseña que solo se aleatoriza usando un timestamp. En este caso, podría ser posible desencadenar dos restablecimientos de contraseña para dos usuarios diferentes que utilicen el mismo token.
Lo único que debemos hacer es sincronizar las solicitudes para que generen el mismo timestamp
En este laboratorio vemos como aplicar esta técnica:
- Exploiting time-sensitive vulnerabilities - https://justice-reaper.github.io/posts/Race-Conditions-Lab-5/
Cheatsheet
Usaremos estas cheatsheet para facilitar la detección y explotación de esta vulnerabilidad:
- Hacking tools https://justice-reaper.github.io/posts/Hacking-Tools/
¿Cómo detectar y explotar una race condition?
Teniendo en cuenta que los términos y herramientas mencionados a continuación se encuentran en la cheatsheet mencionada anteriormente, llevaremos a cabo los siguientes pasos:
Instalarla extensiónTurbo IntruderIdentificarunendpoint críticopara laseguridadque puedapresentarunriesgo potencial de colisiónDesde el
Repeater,creamosungrupocon laspeticionesque vamos ausarparacausarlarace condition. Normalmente, lasrace conditionsson másfácilesdeexplotarsienviamos entre 20 y 30 peticiones a la vez, sin embargo,hay ocasiones en las que es mejor utilizar solamente 2 peticiones. Laúnica diferenciaes que esprobablequetengamos realizar más intentos hasta que obtengamos un colisión si solo utilizamos 2 peticionesDependiendo de la funcionalidad, tendremos queusarla opciónSend group in sequence (single connection)oSend group in sequence (separate connections)Una vez enviadas las peticiones usando alguno de los dos formas, tenemos quefijarnosen eldelayde laspeticiones, si vemos que ladiferenciaesmuy grandevamos a tener que usar latécnicadeconnection warmingo la deabusing rate or resource limitspara hacer queel delay entre peticiones sea de unos 10 milisegundos o de máximo 50 milisegundos. Amenor delay,mayor es la probabilidad de que se produzca una race window y por lo tanto, también hay mayor probabilidad de que podamos explotar la race condition con éxitoUna vez hayamos logrado que el delay entre peticiones se encuentre entre 0 milisegundos y 50 milisegundos, tenemos queenviarlaspeticionesusandoSend group (parallel)Hay ocasiones en las que se implementan mecanismos de bloqueo basados en la sesión. Esto puedeprovocarquepara la misma sesión sola podamos mandar una petición a la vez para ejecutar una acción. Sin embargo, es posiblebypassearestarestricciónsienviamosunapeticióndesdedos sesiones diferentesSi
tenemosuncódigo de descuento,podemos intentar aplicarlo varias vecesmediante unarace conditionA la
horadecomprarunproductopodemosañadirunproducto muy baratoa lacesta. Si hay unarace condition, podría ser posibleañadir un producto a la cesta cuyo costo supere el monto de dinero que tenemos antes de que se realice el checkout. De esta forma,obtendríamos 2 productos por el precio de 1, ya queel segundo producto no se nos cobraríaSi nos
encontramoscon unpanel de login, el cualnos impide ejecutar un ataque de fuerza bruta, podemosutilizarlaextensión Turbo Intruder de Burpsuiteparasaltarnosesterate limitmediante unarace conditionSi tenemos la
opcióndeproporcionar un emaila lahoradecambiar la contraseña,pedir un desbloqueo de cuenta,cambiar nuestro emailocualquier otra información de valor, podemos hacer quenos llegue a nuestro email la información de otro usuario a través de una race condition
¿Cómo prevenir las vulnerabilidades provocadas por una race condition?
Cuando una sola solicitud puede hacer que una aplicación transicione a través de sub-estados invisibles, entender y predecir su comportamiento es extremadamente difícil. Esto hace que la defensa sea poco práctica. Para asegurar correctamente una aplicación, debemos eliminar los sub-estados de todos los endpoints sensibles aplicando las siguientes estrategias:
Evitar mezclar datos procedentes de diferentes lugares de almacenamientoAsegurarnos de que los endpoints sensibles hagan cambios de estado atómicos utilizando las funciones de concurrencia de la base de datos. Por ejemplo,usar una sola transacción en la base de datos para comprobar que el pago coincide con el valor del carrito y confirmar el pedidoComo
medidadedefensa en profundidad,aprovecharlascaracterísticasdeintegridadyconsistenciade labase de datoscomo lasrestricciones de unicidad de las columnas. Es decir, podemos hacer queciertas columnas no acepten valores duplicadosNo debemos usar un sistema de almacenamiento de datos para proteger otro. Por ejemplo,no debemos confiar en las sesiones para evitar que ataquen la base de datos haciendo demasiadas peticionesAsegurarnosde quenuestro framework de gestión de sesiones mantenga las sesiones internamente consistentes.Actualizar variables de sesión individualmente en lugar de en grupo puede ser una optimización tentadora, pero es extremadamente peligroso. Esto tambiénaplicaa losORMs, alocultar conceptoscomo lastransacciones,asumen la responsabilidad total sobre ellasEn algunas
arquitecturas, puede ser adecuadoevitar por completo el estado del lado del servidor. En su lugar,se podría usar cifrado para trasladar el estado al lado del cliente, por ejemplo, mediante JWTs.Debemos tener en cuenta que esto conlleva sus propios riesgos, como ya hemoscubiertoampliamente en laguía sobre ataques a JWTshttps://justice-reaper.github.io/posts/JWT-Attacks-Guide/