Multi-endpoint race conditions
Laboratorio de Portswigger sobre Race Conditions

Certificaciones
- eWPT
- eWPTXv2
- OSWE
- BSCP
Descripción
Este laboratorio tiene una race condition en el flujo de compra, lo que nos permite comprar artículos a un precio no intencionado. Para resolver el laboratorio, tenemos que comprar una chaqueta Lightweight L33t de cuero. Podemos iniciar sesión con las credenciales wiener:peter
Guía de race conditions
Antes de completar este laboratorio es recomendable leerse esta guía de race conditions https://justice-reaper.github.io/posts/Race-Conditions-Guide/
Resolución
Al acceder a la web vemos esto
Si hacemos click sobre My account nos podemos loguear con las credenciales wiener:peter
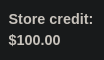
Después de iniciar sesión vemos que tenemos 100 dólares en la cuenta
Podemos añadir un artículo a la cesta pulsando sobre View details > add to cart. Si posteriormente pulsamos sobre la cesta podemos ver el artículo añadido
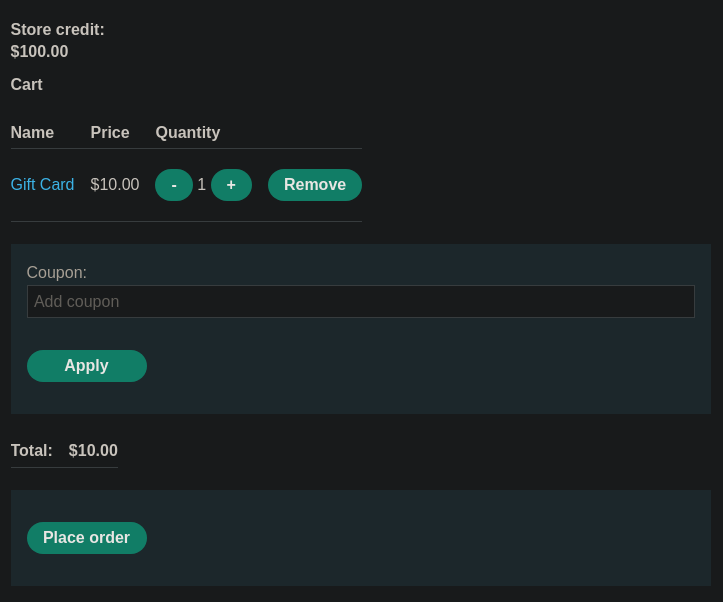
Al comprar la Gift Card su código para que podamos canjearlo
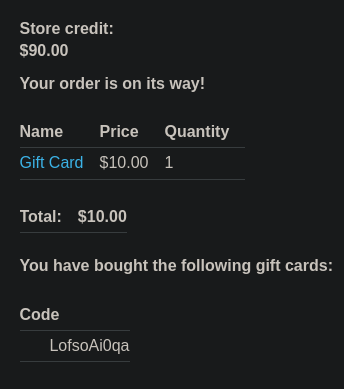
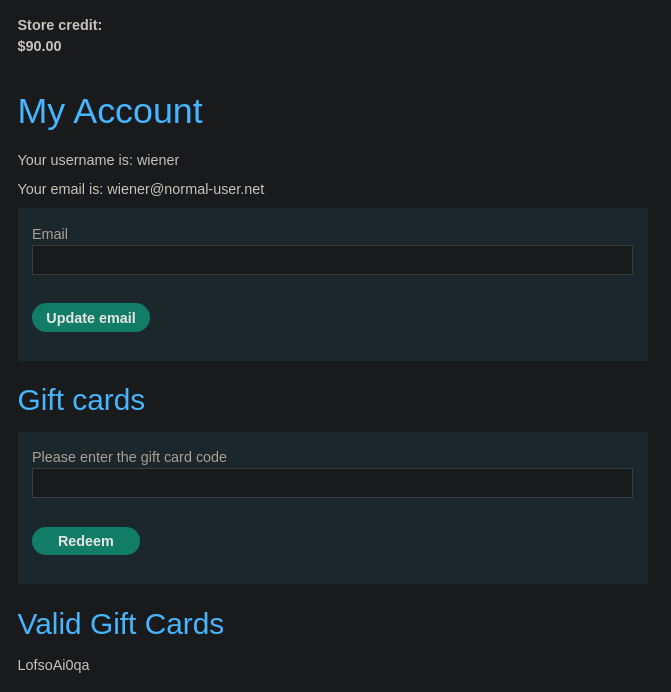
Si nos dirigimos a My account vemos que podemos canjear la Gift Card
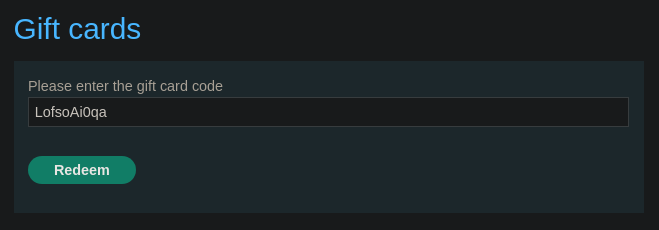
Si en el apartado de Gift cards canjeamos el código obtendremos 10 dólares
A continuación, vamos a capturar varias peticiones y mandarlas al Repeater, la primera va ser la de añadir el artículo Lightweight "l33t" Leather Jacket a la cesta y la segunda va a ser la de Place order
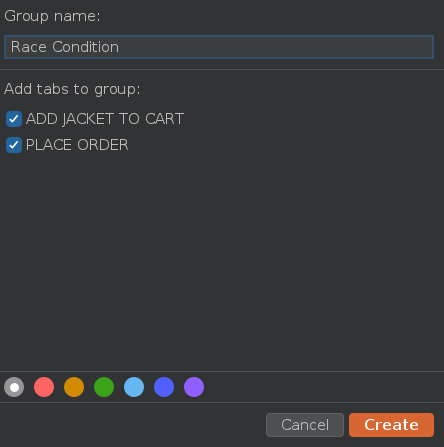
Pinchamos sobre los tres puntos y creamos un grupo pulsando en Create tab group
El orden de las peticiones tiene que ser este. Primero tenemos que añadir el artículo Gift Card a la cesta, lo cual lo tenemos que hacer desde fuera del grupo, podemos hacerlo desde el Repeater o manualmente desde la web. Posteriormente tenemos que comprarlo y mientras que se procesa la orden de compra debemos añadir el artículo Lightweight "l33t" Leather Jacket a la cesta para que no se nos cobre este último artículo

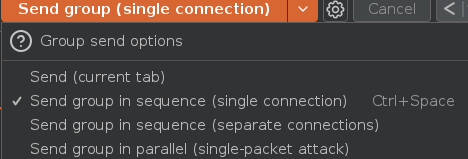
Vamos a enviar todas las peticiones en grupo usando la opción Send group in sequence (single connection), usamos esta opción porque la posible race condition se va a dar en una misma sesión debido a que estamos logueados. Esto se hace para saber si hay algún delay entre las peticiones
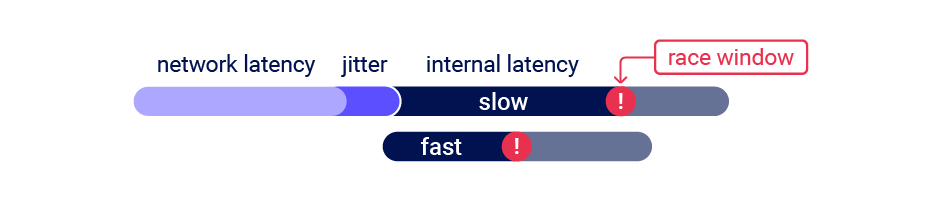
En la parte inferior derecha podemos ver el delay de las peticiones. Vemos que hay bastante diferencia entre los delays de las diferentes peticiones

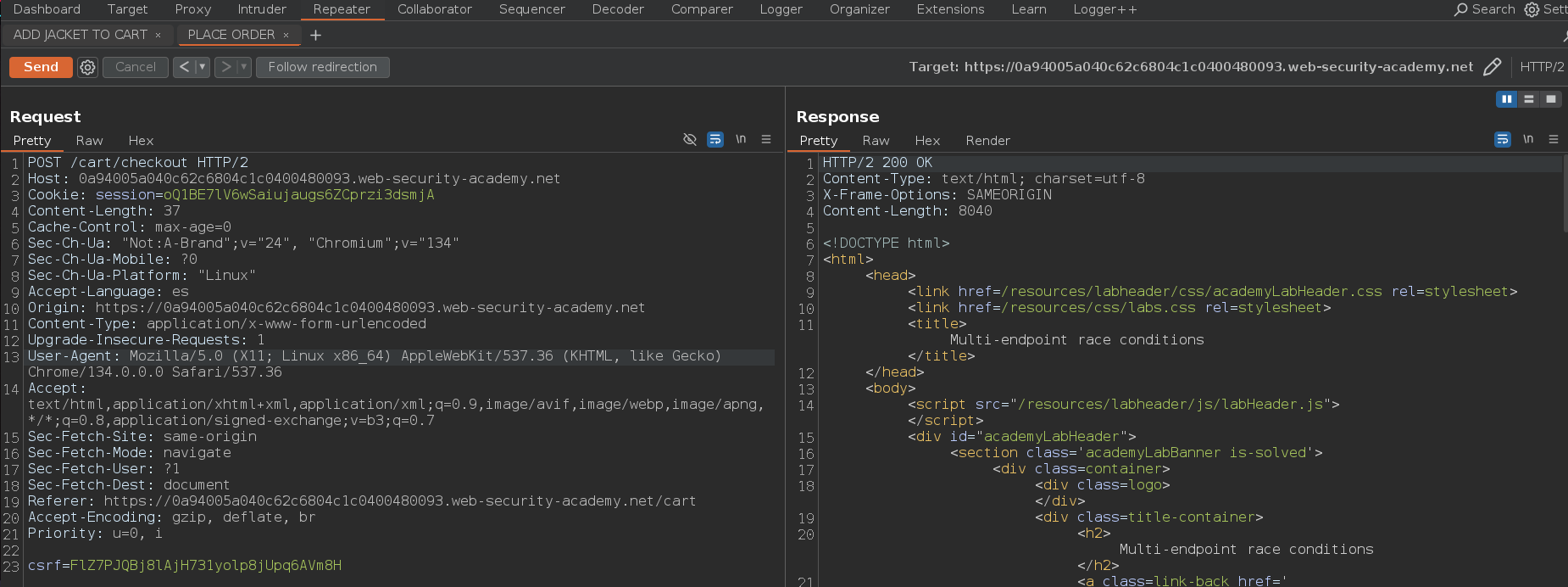
Para solucionar este problema vamos emplear una la técnica connection warming, así que para ello vamos a añadir al grupo una petición al directorio raíz / de la web. Es importante que esta petición este al principio del grupo
Testeamos la race condicion nuevamente con Send group in sequence (single connection)
En este caso, la diferencia de delay es menor que en el caso anterior


Añadimos la Gift Card a la cesta, ya sea desde el Repeater pero fuera del grupo o de forma manual desde la web

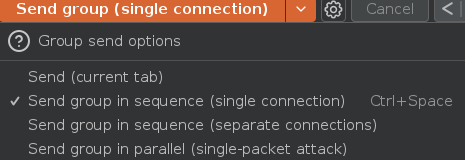
Una vez hecho esto, seleccionamos la opción Send group in parallel (single-packet attack) y efectuamos un single-packet attack. Aunque las condiciones sean aparentemente idóneas puede ser que tengamos que ejecutar el ataque varias veces para que funcione

Si renderizamos la respuesta vemos que la orden de compra se ha llevado a cabo con éxito
Aunque funciona correctamente de esta forma, he obtenido mayor porcentaje de éxito si añado otra Gift Card en la race condition. Es decir, Añadimos una Gift Card a la cesta, ya sea desde el Repeater pero fuera del grupo o de forma manual desde la web y posteriormente añadimos otra mediante la race condition
